使用ResNet18预训练模型 由于笔记本性能太差,所以在服务器上运行的,显卡配置为4090。经大量实验判断,初始学习率为0.01最后效果较差,所以初始学习率应设为0.001。全部代码代码已上传到:https://github.com/wp-a/-CIFAR10-.git
库函数导入 1 2 3 4 5 6 7 8 9 import matplotlib.pyplot as pltimport torchimport torch.nn as nnimport torchvisionimport torchvision.transforms as transformsfrom sklearn.metrics import confusion_matrix, classification_reportfrom itertools import chainimport multiprocessingdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" )
数据集加载及增强操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 transform_train = transforms.Compose([ transforms.Resize(224 ), transforms.RandomHorizontalFlip(), transforms.RandomRotation(10 ), transforms.ToTensor(), transforms.Normalize((0.4914 , 0.4822 , 0.4465 ), (0.2470 , 0.2435 , 0.2616 )) ]) transform_test = transforms.Compose([ transforms.Resize(224 ), transforms.ToTensor(), transforms.Normalize((0.4914 , 0.4822 , 0.4465 ), (0.2470 , 0.2435 , 0.2616 )) ]) train_set = torchvision.datasets.CIFAR10("./data" , download=True , transform=transform_train) test_set = torchvision.datasets.CIFAR10("./data" , download=True , train=False , transform=transform_test) batch_size = 64 train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True , num_workers=0 ) test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=False , num_workers=0 ) classes = ('plane' , 'car' , 'bird' , 'cat' , 'deer' , 'dog' , 'frog' , 'horse' , 'ship' , 'truck' ) def output_label (label ): output_mapping = { 0 : "plane" , 1 : "car" , 2 : "bird" , 3 : "cat" , 4 : "deer" , 5 : "dog" , 6 : "frog" , 7 : "horse" , 8 : "ship" , 9 : "truck" } input = (label.item() if type (label) == torch.Tensor else label) return output_mapping[input ]
加载预训练模型 1 2 3 4 5 6 7 def get_resnet18 (pretrained=True ): model = torchvision.models.resnet18(pretrained=pretrained) model.fc = nn.Linear(512 , 10 ) return model model = get_resnet18() model = model.to(device)
模型训练超参数设置 1 2 3 4 5 6 7 8 9 10 11 12 13 criterion = nn.CrossEntropyLoss() learning_rate = 0.001 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) def exp_lr_scheduler (optimizer, epoch, init_lr=0.001 , lr_decay_epoch=2 ): lr = init_lr * (0.1 ** (epoch // lr_decay_epoch)) if epoch % lr_decay_epoch == 0 : print (f'LR is set to {lr} ' ) for param_group in optimizer.param_groups: param_group['lr' ] = lr return optimizer
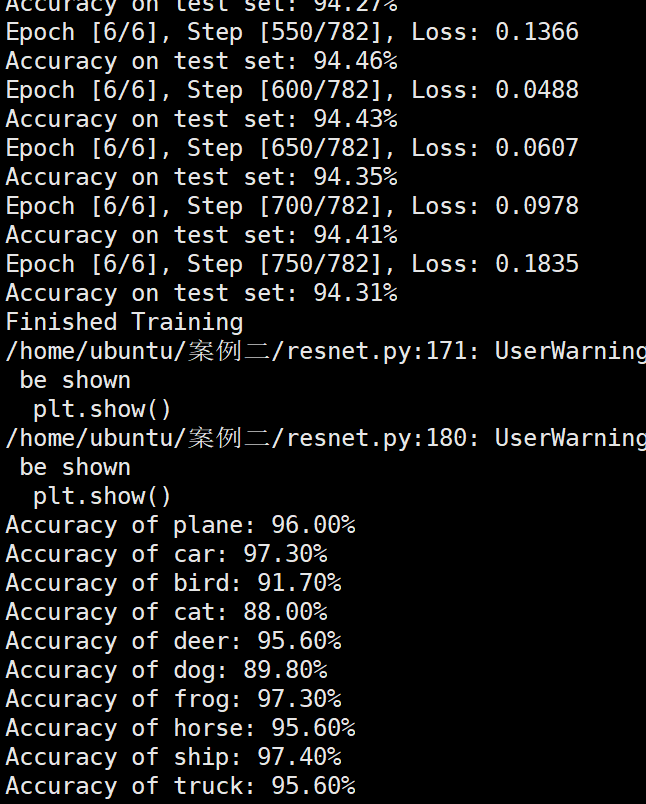
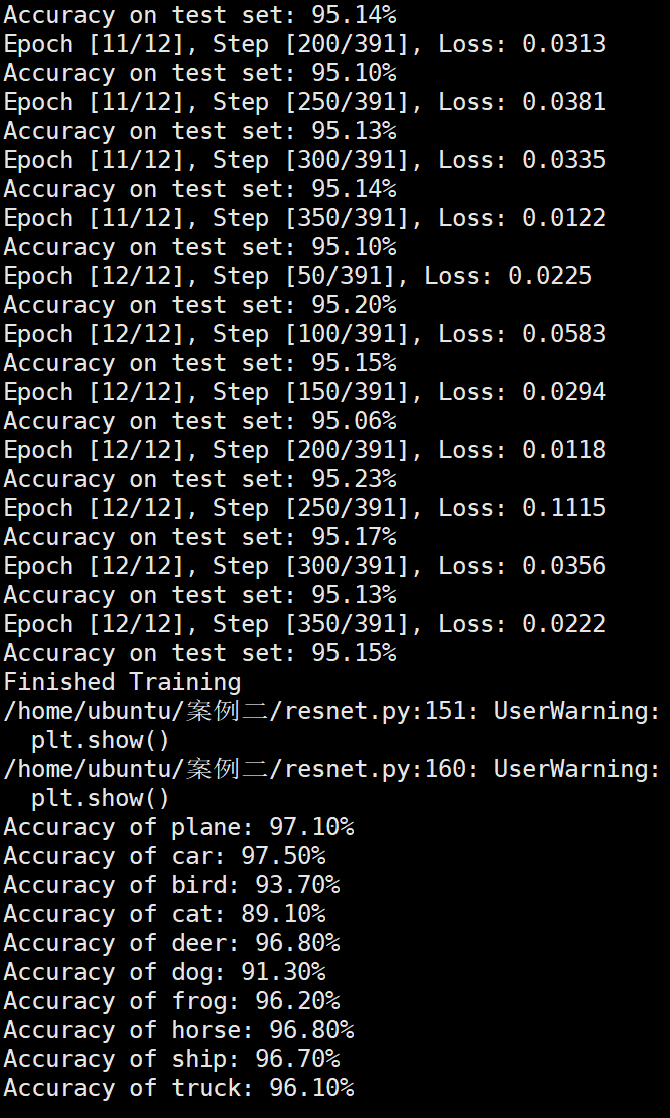
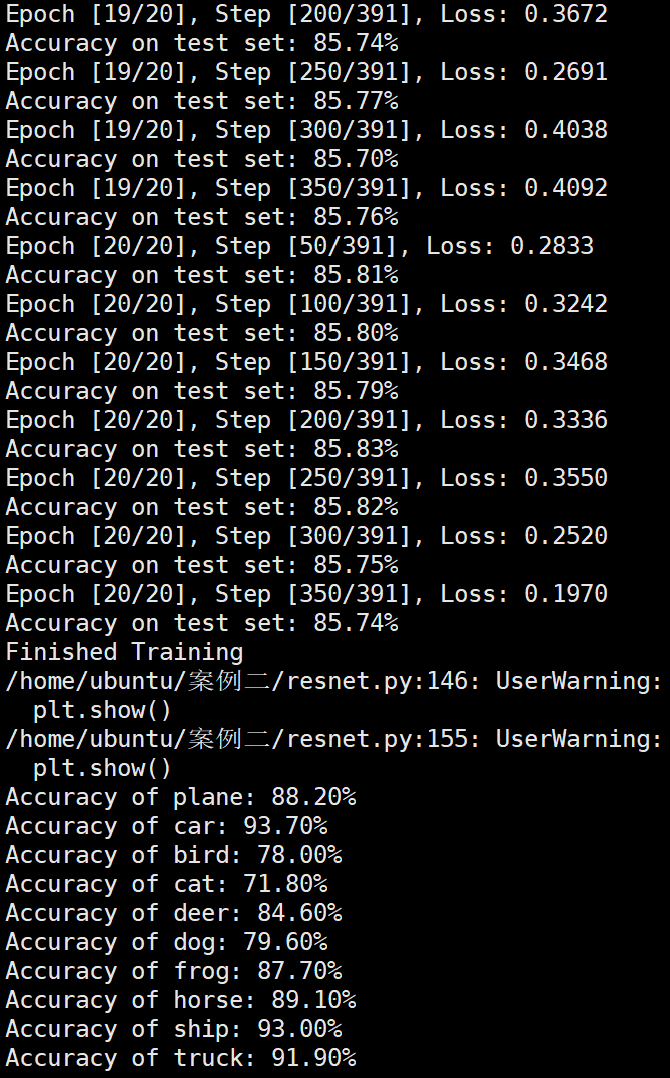
模型训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 num_epochs = 6 count = 0 loss_list = [] iteration_list = [] accuracy_list = [] predictions_list = [] labels_list = [] for epoch in range (num_epochs): model.train() running_loss = 0.0 optimizer = exp_lr_scheduler(optimizer, epoch, init_lr=learning_rate, lr_decay_epoch=2 ) for i, (images, labels) in enumerate (train_loader): images, labels = images.to(device), labels.to(device) outputs = model(images) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() count += 1 if (i + 1 ) % 50 == 0 : print (f'Epoch [{epoch + 1 } /{num_epochs} ], Step [{i + 1 } /{len (train_loader)} ], Loss: {loss.item():.4 f} ' ) model.eval () total = 0 correct = 0 test_predictions = [] test_labels = [] with torch.no_grad(): for images, labels in test_loader: images, labels = images.to(device), labels.to(device) test_labels.extend(labels.cpu().numpy()) outputs = model(images) _, predicted = torch.max (outputs.data, 1 ) test_predictions.extend(predicted.cpu().numpy()) total += labels.size(0 ) correct += (predicted == labels).sum ().item() accuracy = 100 * correct / total print (f'Accuracy on test set: {accuracy:.2 f} %' ) loss_list.append(loss.item()) iteration_list.append(count) accuracy_list.append(accuracy) predictions_list.append(test_predictions) labels_list.append(test_labels) model.train() print ('Finished Training' )
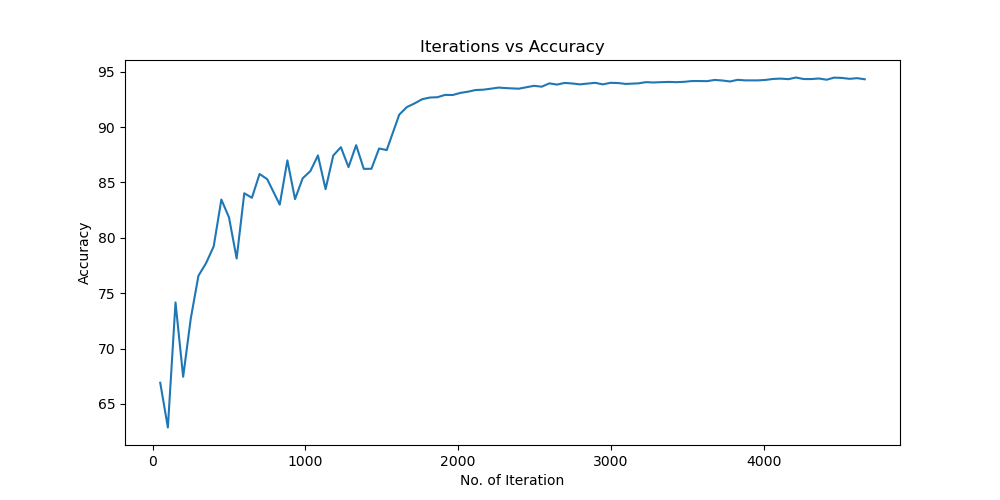
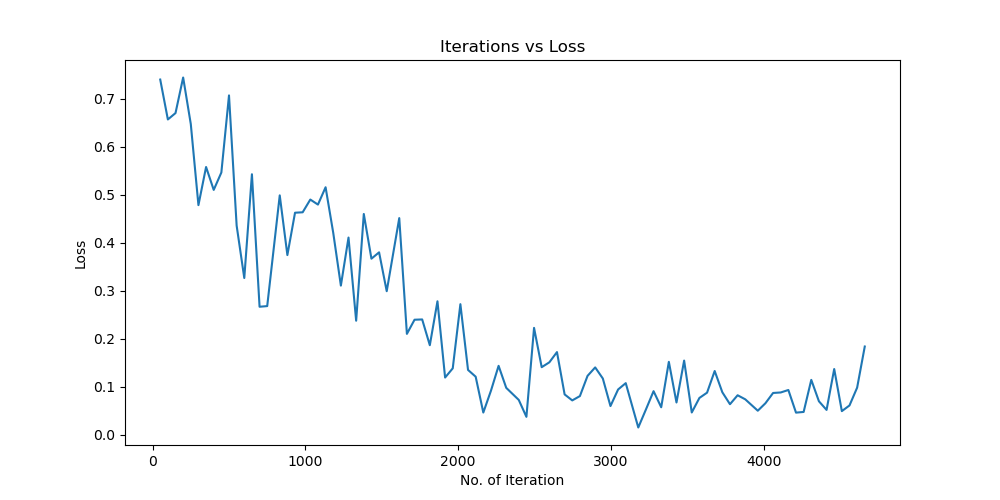
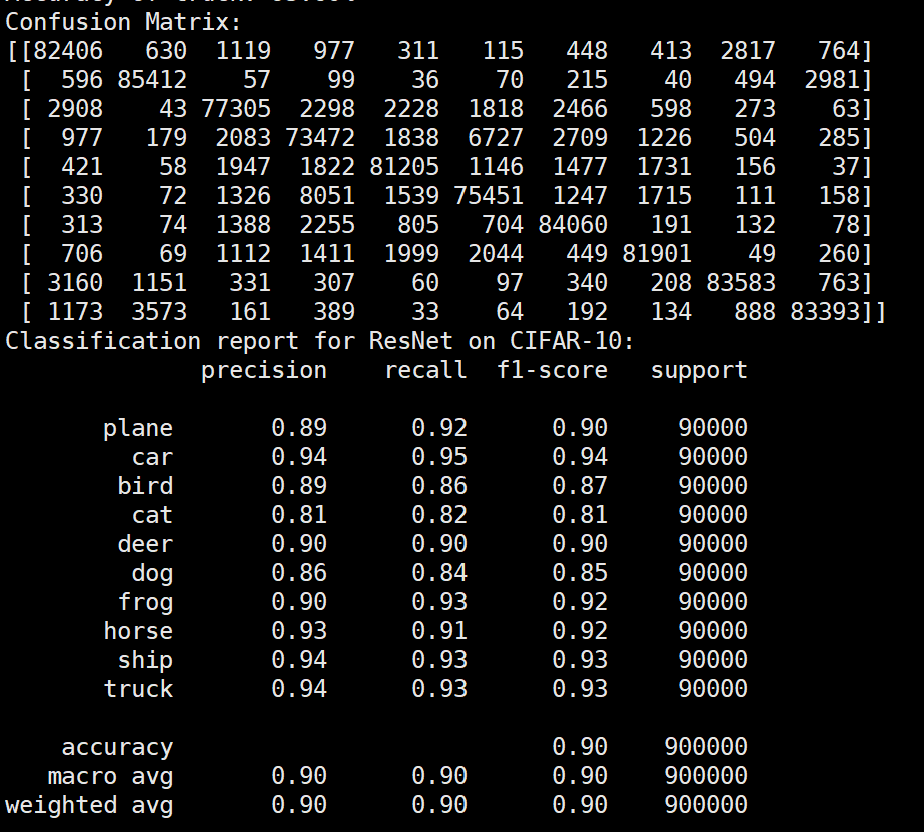
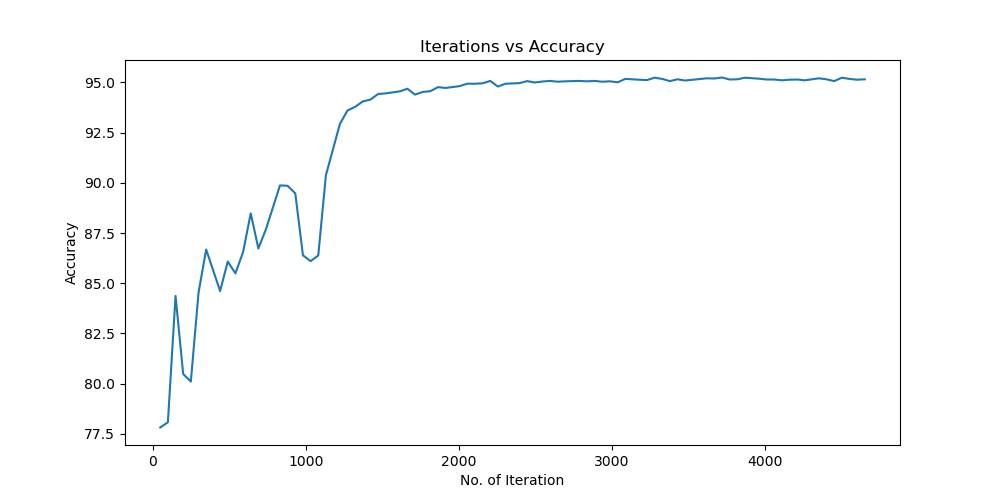
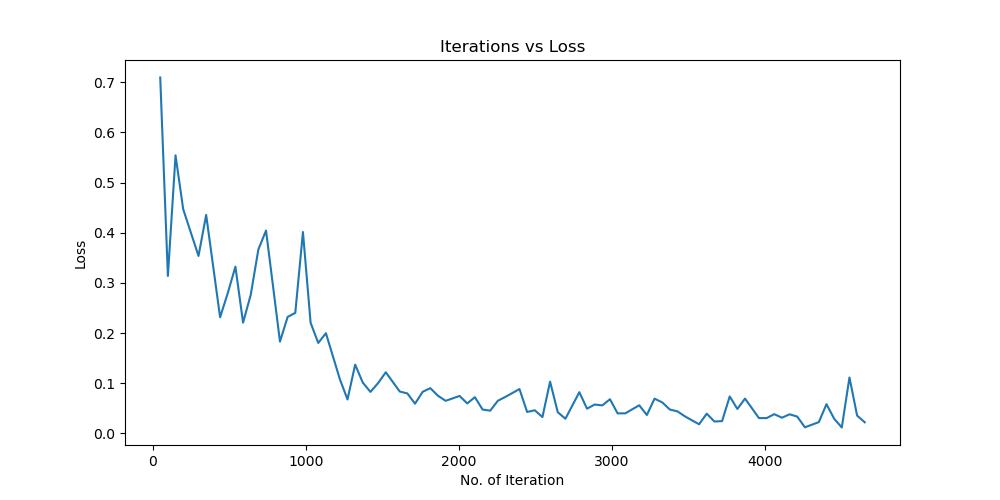
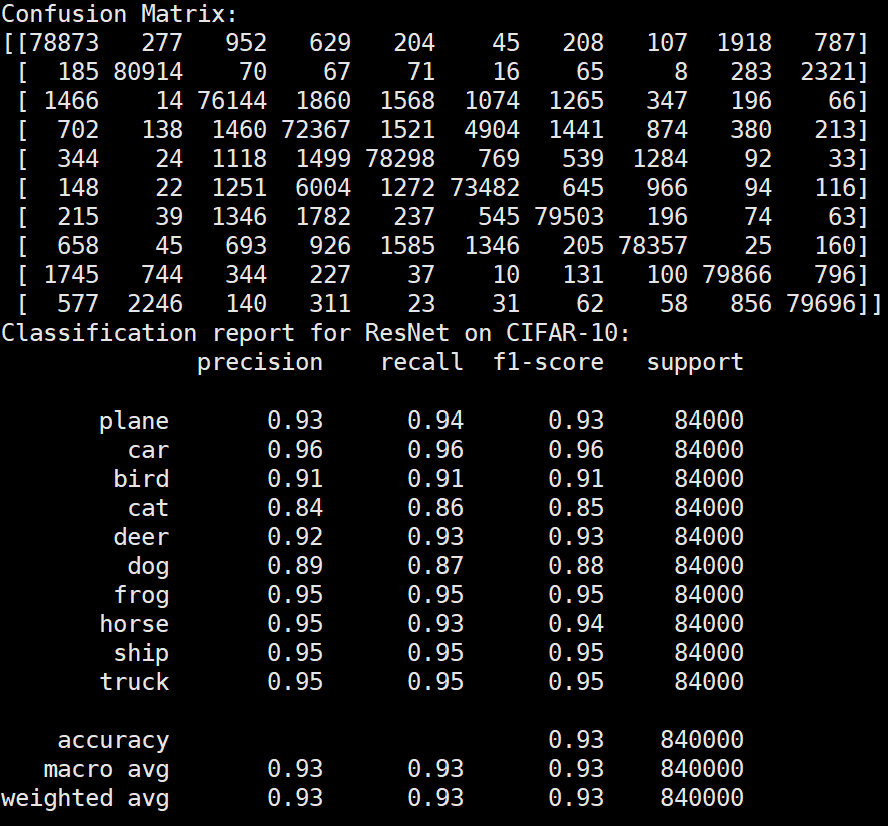
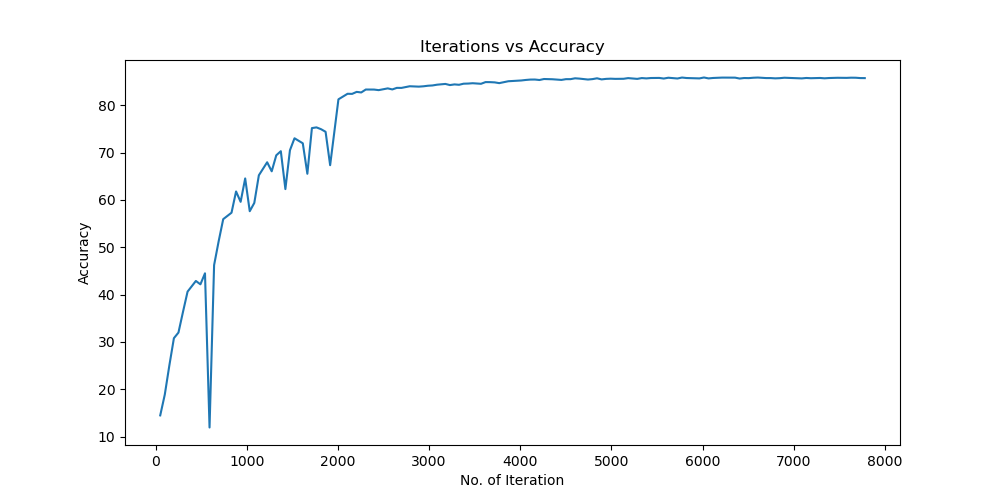
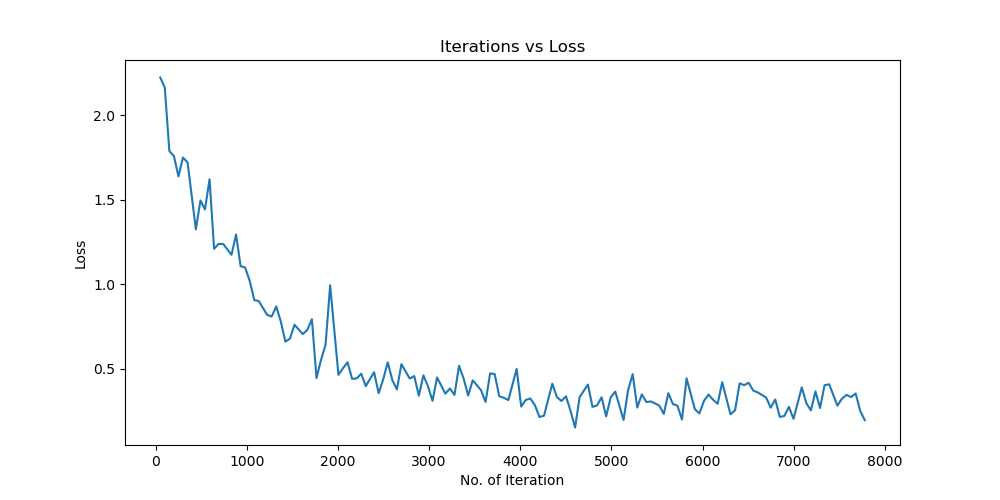
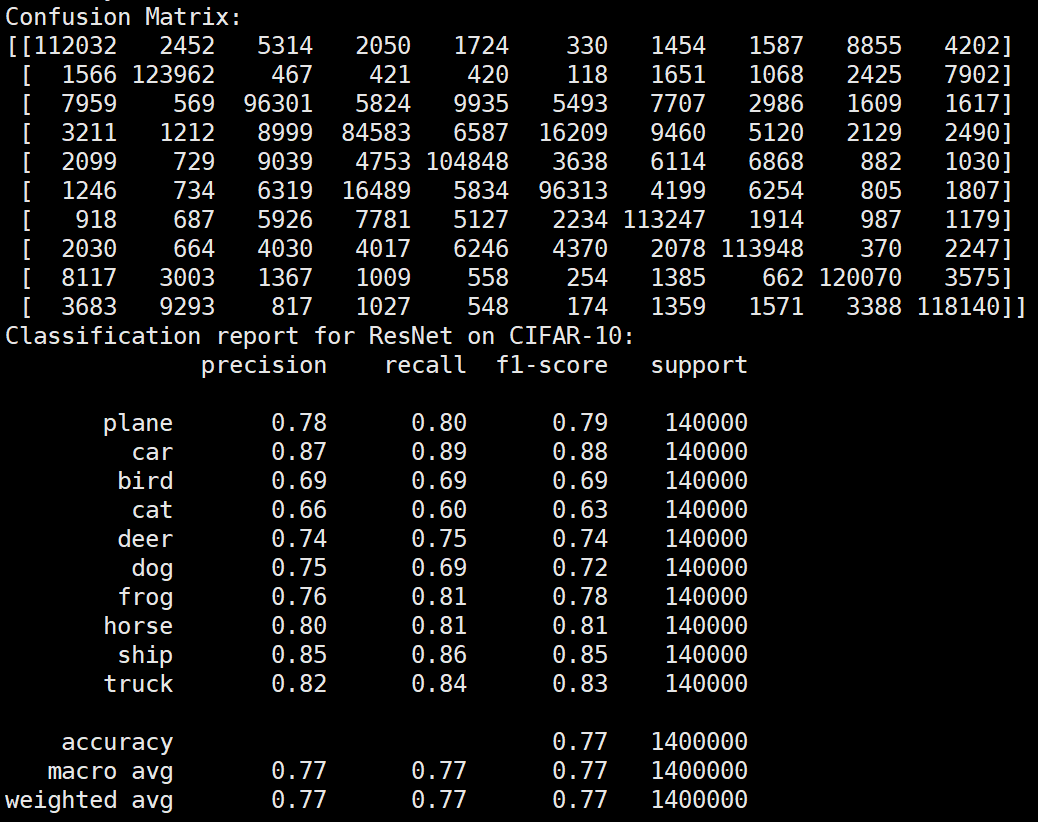
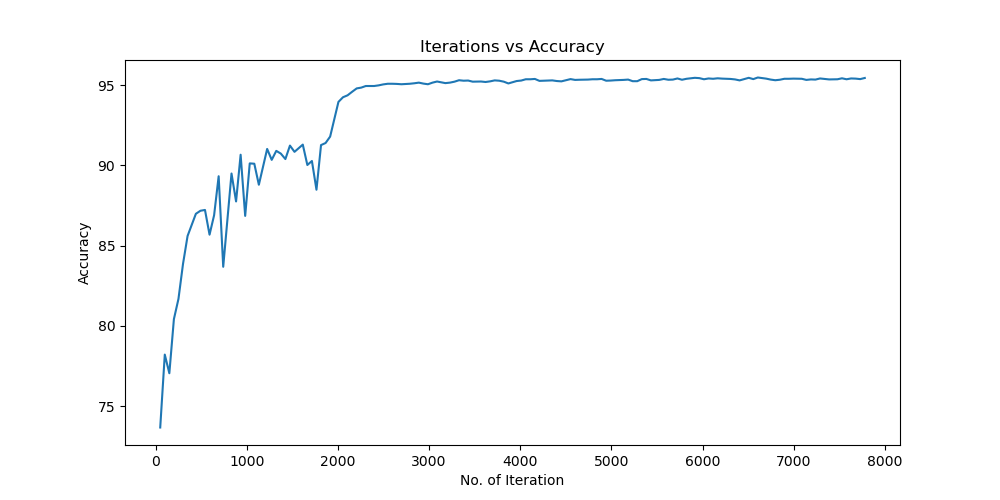
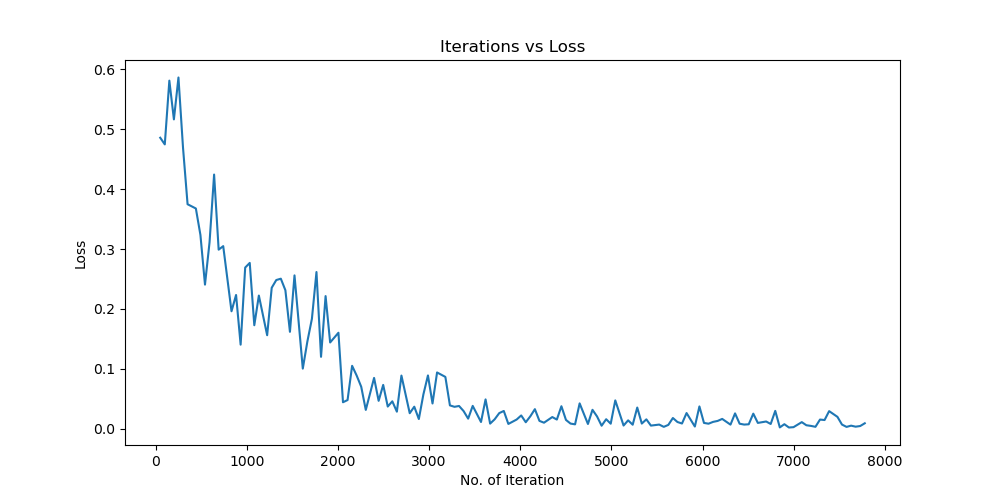
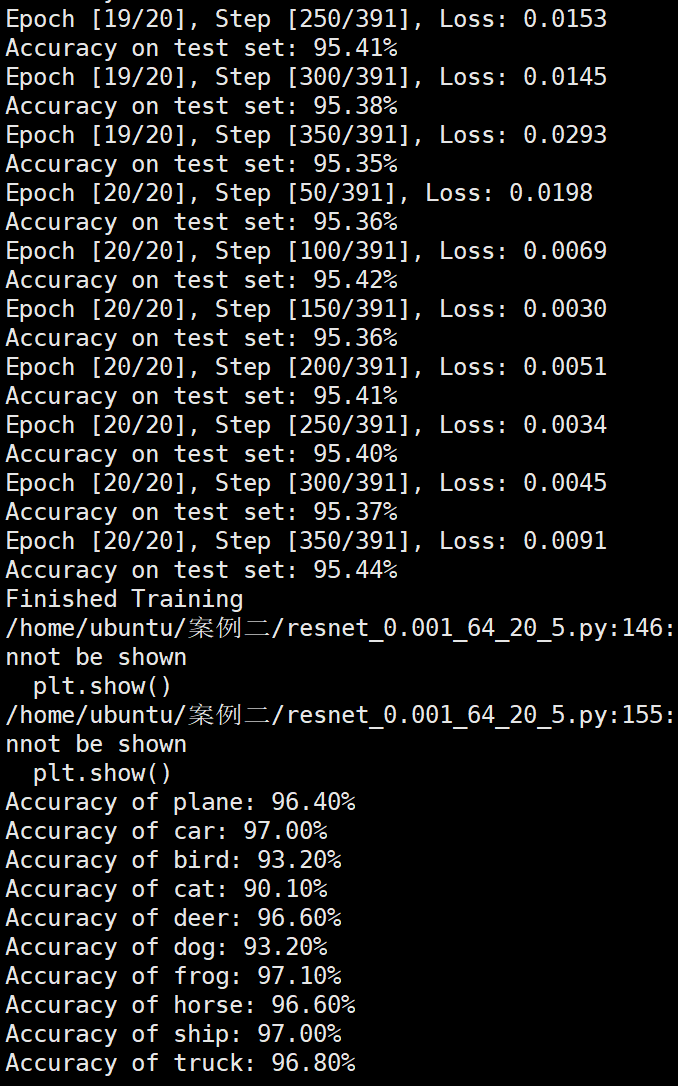
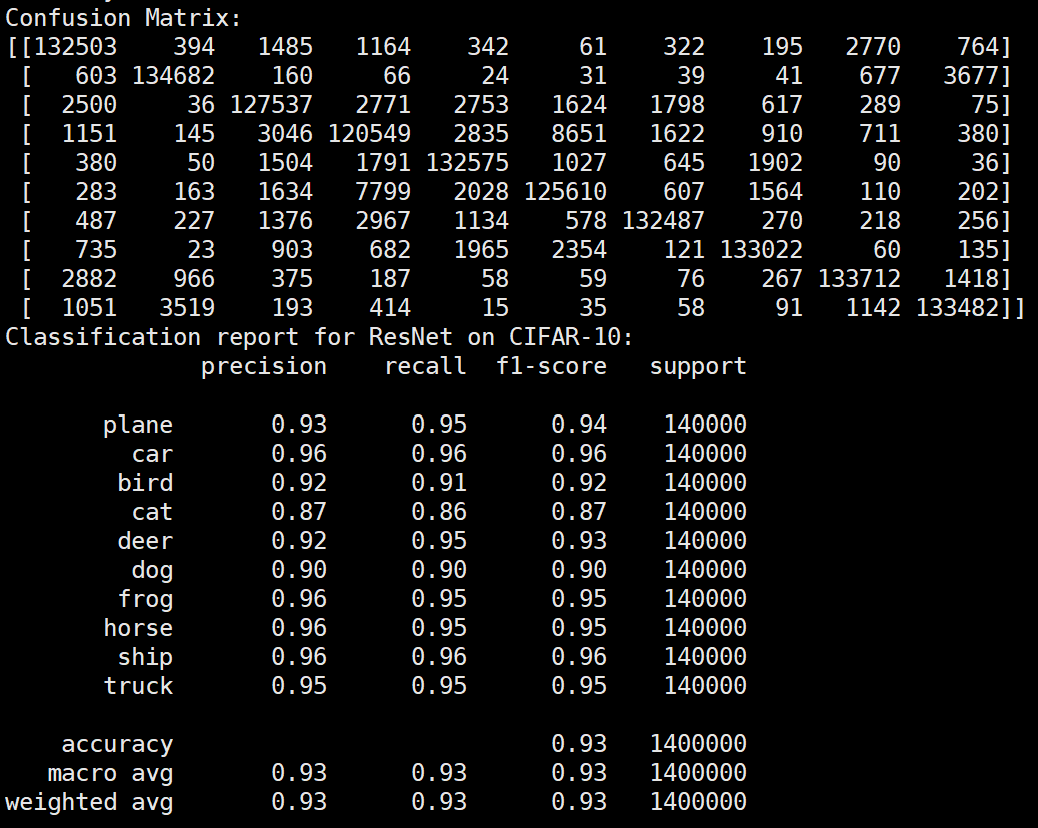
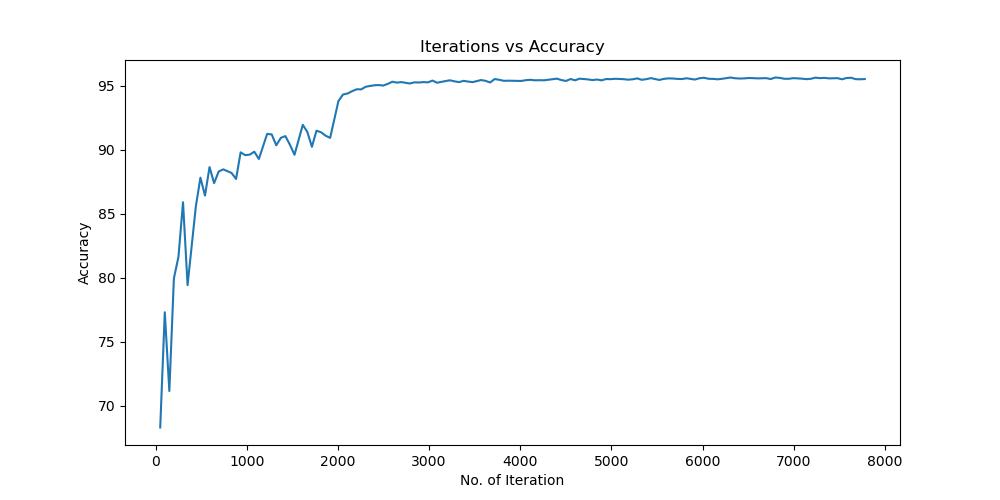
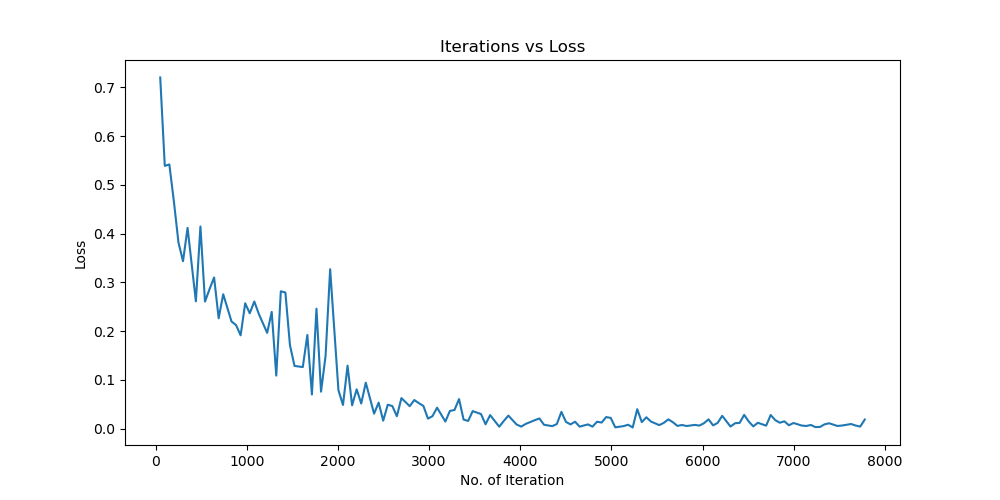
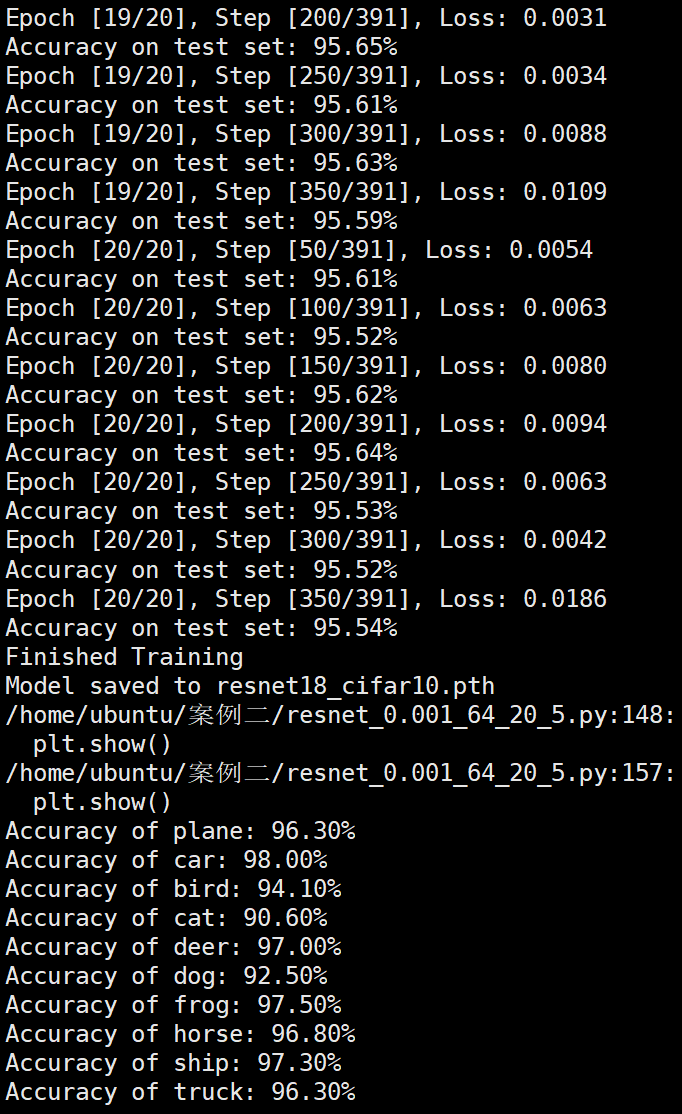
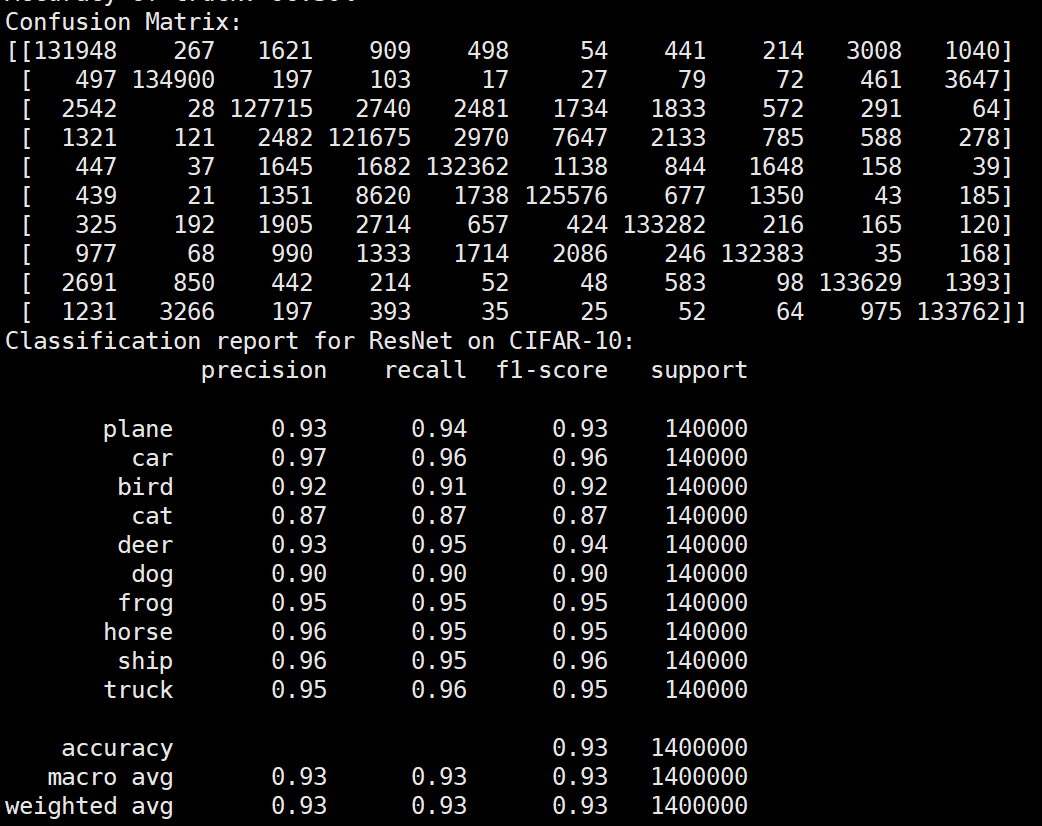
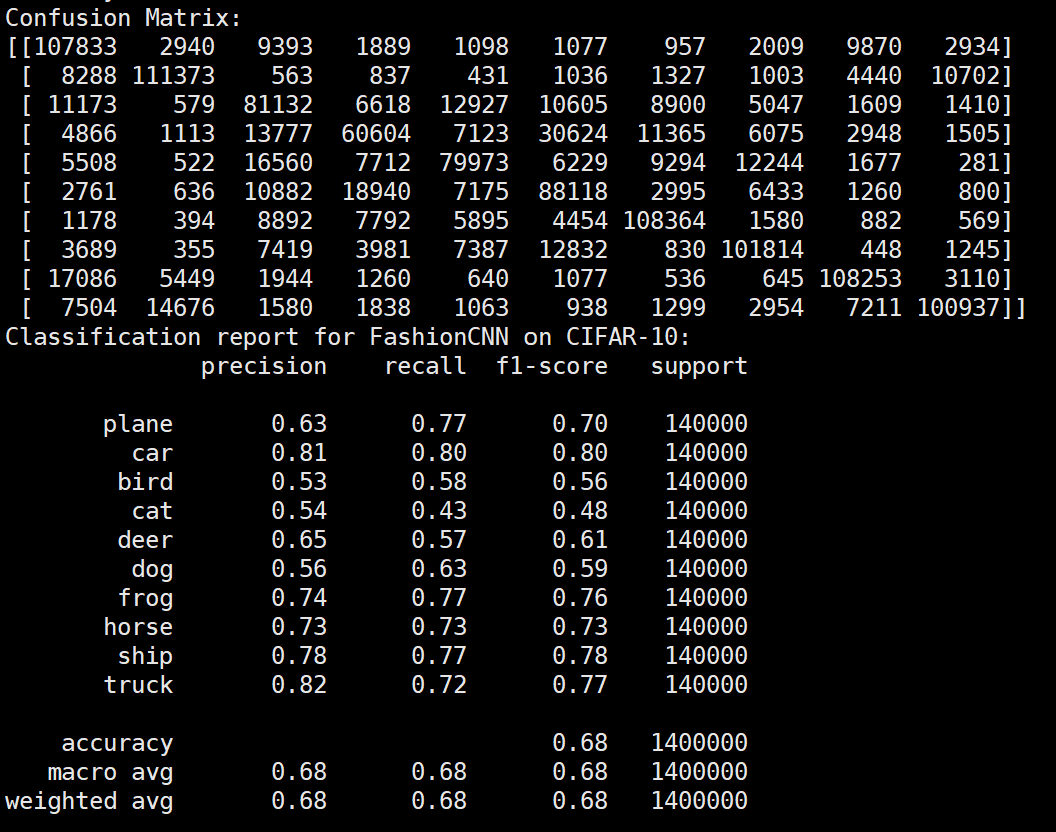
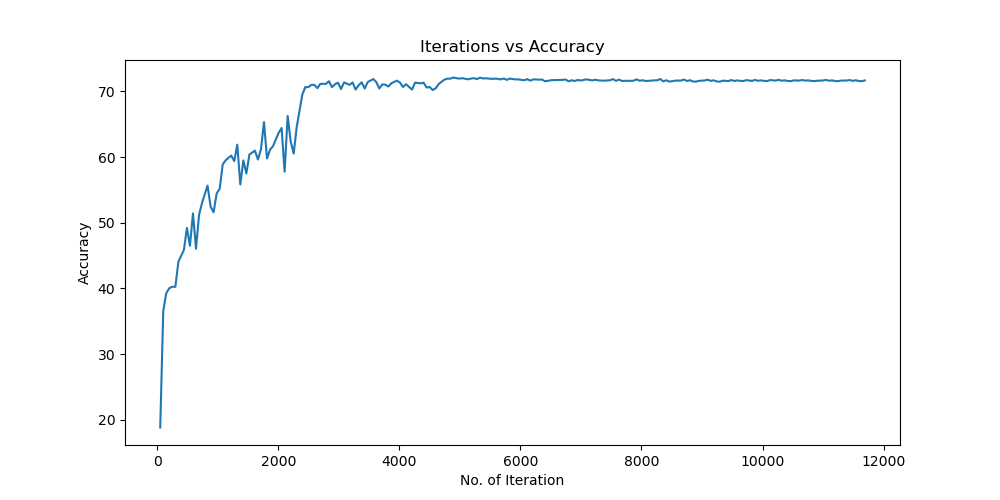
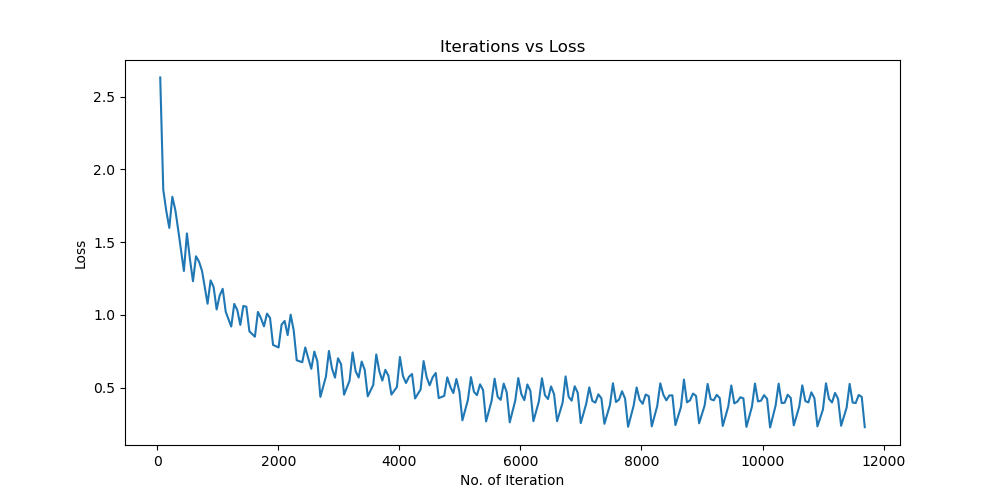
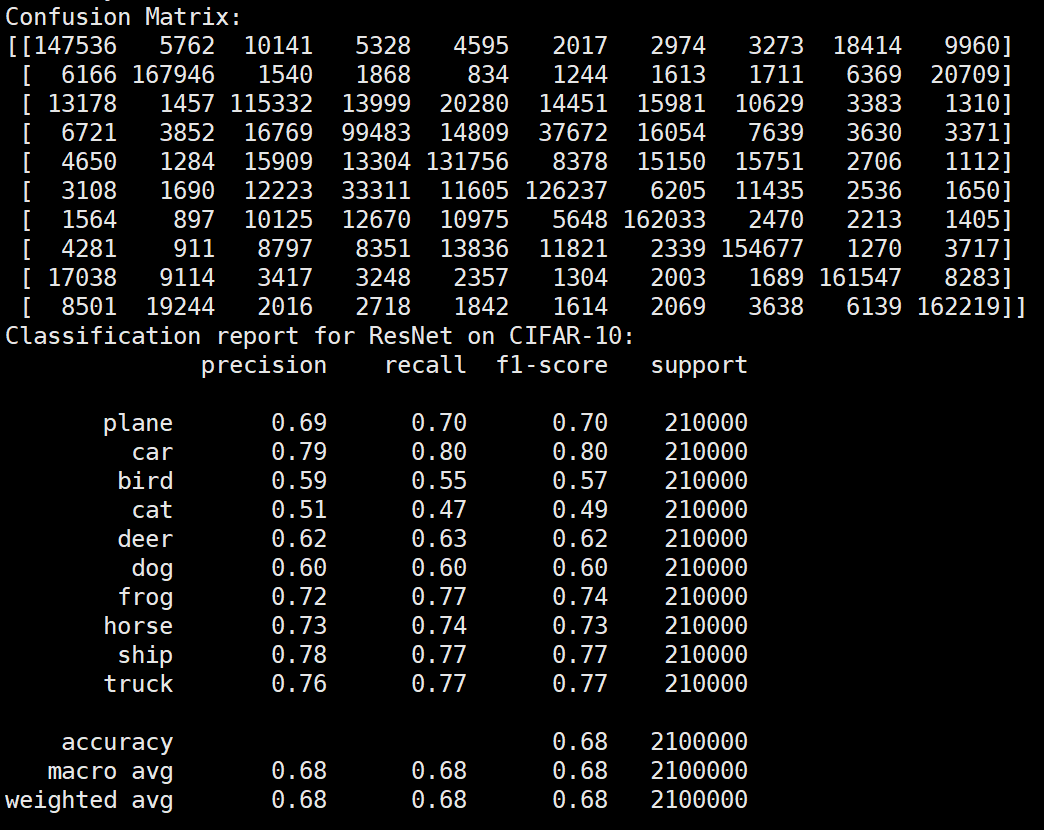
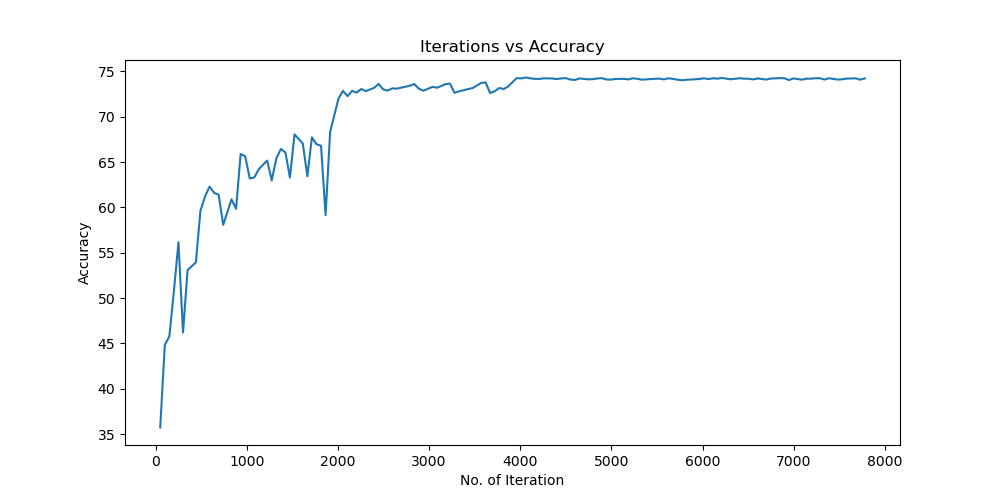
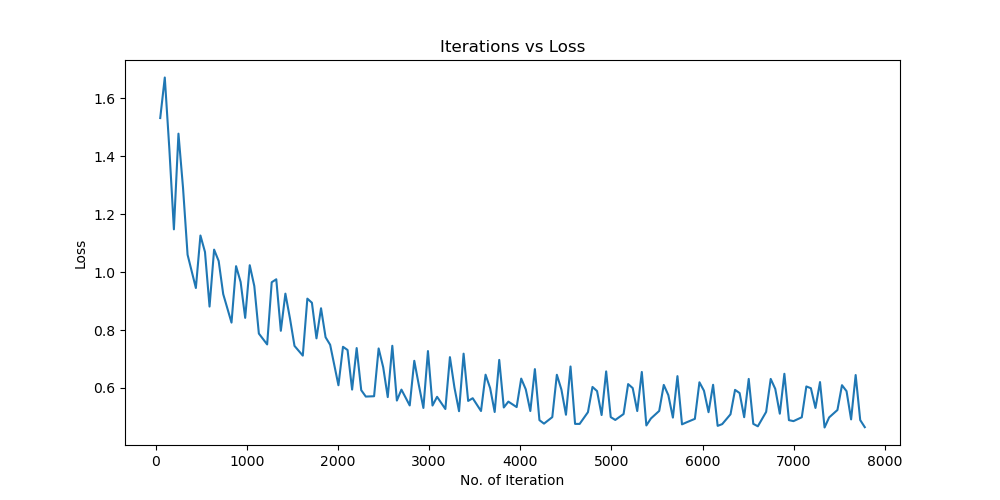
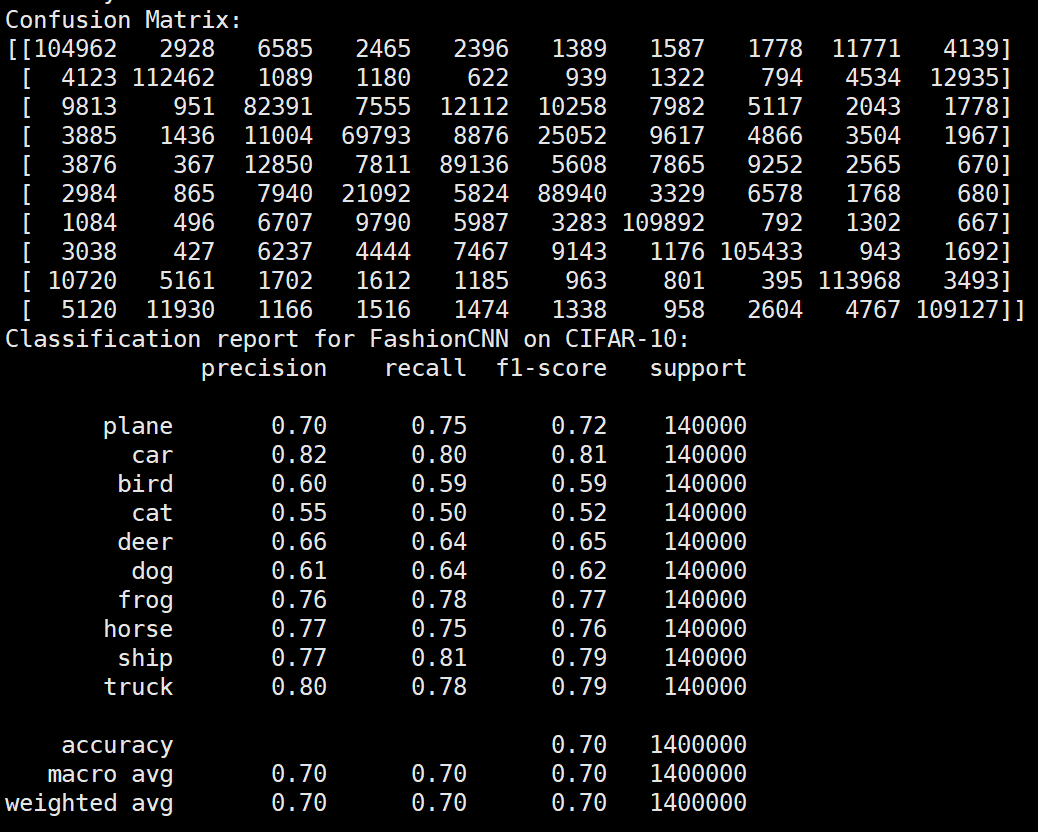
实验结果保存 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 torch.save(model.state_dict(), 'resnet18_cifar10.pth' ) print ('Model saved to resnet18_cifar10.pth' )plt.figure(figsize=(10 , 5 )) plt.plot(iteration_list, loss_list) plt.xlabel("No. of Iteration" ) plt.ylabel("Loss" ) plt.title("Iterations vs Loss" ) plt.savefig('loss_curve.png' ) plt.show() plt.figure(figsize=(10 , 5 )) plt.plot(iteration_list, accuracy_list) plt.xlabel("No. of Iteration" ) plt.ylabel("Accuracy" ) plt.title("Iterations vs Accuracy" ) plt.savefig('accuracy_curve.png' ) plt.show() class_correct = [0. for _ in range (10 )] total_correct = [0. for _ in range (10 )] model.eval () with torch.no_grad(): for images, labels in test_loader: images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max (outputs, 1 ) c = (predicted == labels).squeeze() for i in range (labels.size(0 )): label = labels[i] class_correct[label] += c[i].item() total_correct[label] += 1 for i in range (10 ): print (f"Accuracy of {classes[i]} : {100 * class_correct[i] / total_correct[i]:.2 f} %" ) flat_predictions = list (chain.from_iterable(predictions_list)) flat_labels = list (chain.from_iterable(labels_list)) cm = confusion_matrix(flat_labels, flat_predictions) print ("Confusion Matrix:" )print (cm)print ("Classification report for ResNet on CIFAR-10:" )print (classification_report(flat_labels, flat_predictions, target_names=classes))
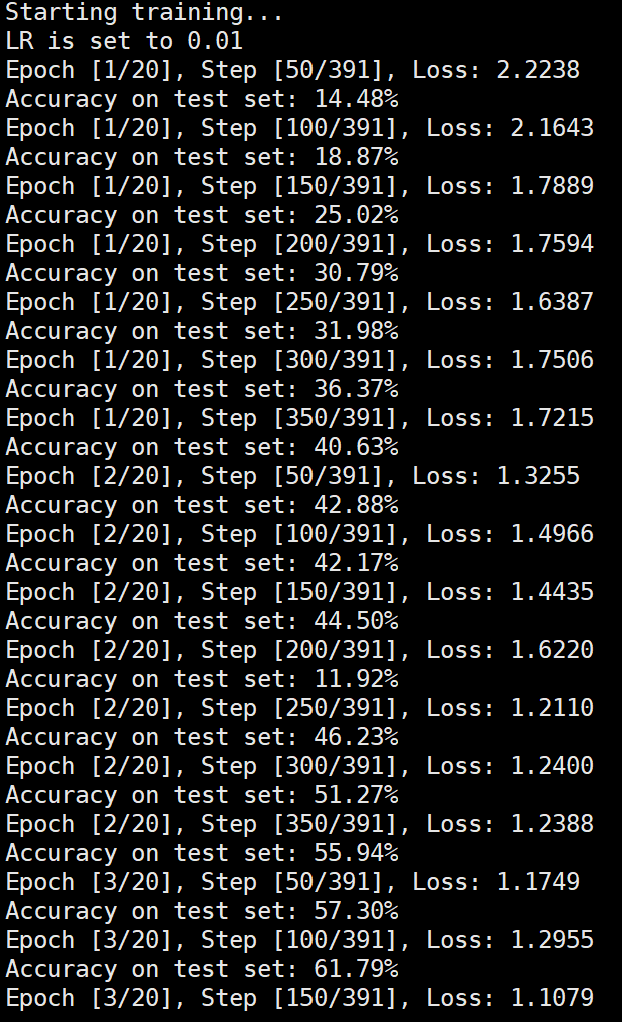
实验结果分析 lr分析 由实验结果可得lr=0.01时,效果较差,所以直接设置初始学习率为0.001可以更节省时间,提高效率。当学习率为1e-6时,发现准确率更新较小,所以准确率最小设置为1e-6。即学习率梯度为1e-3,1e-4,1e-5,1e-6,可以有较好的效果。即令epoch / lr_decay_epoch = 3或4 都可以,具体以epoch大小为准。
lr=0.01 lr=0.001 lr=1e6 batchsize分析 Batchsize:64 epoch:6 lr_decay_epoch:2 初始学习率为0.001 94.46%
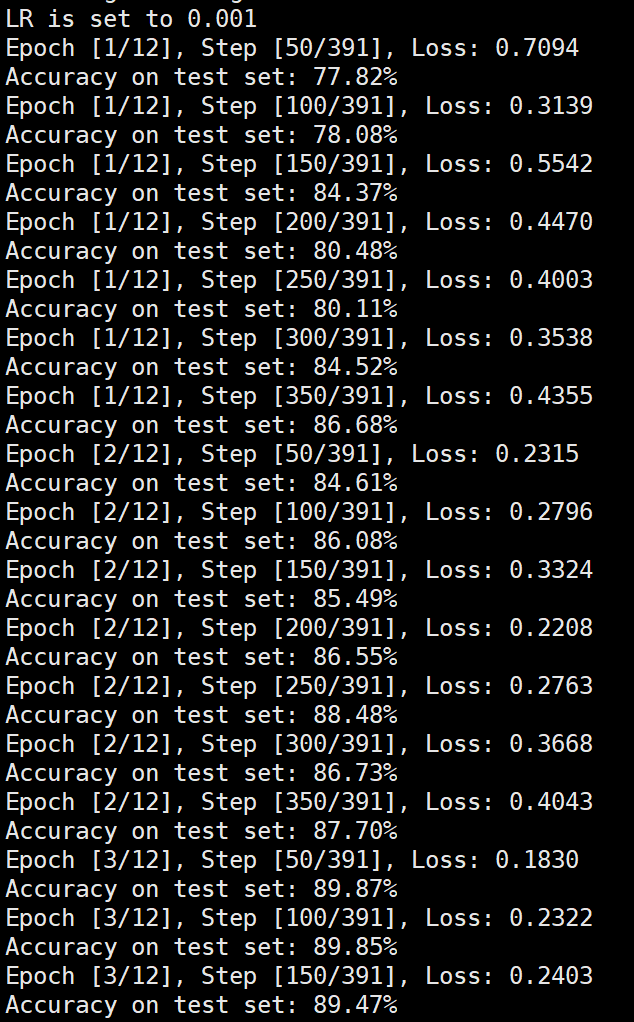
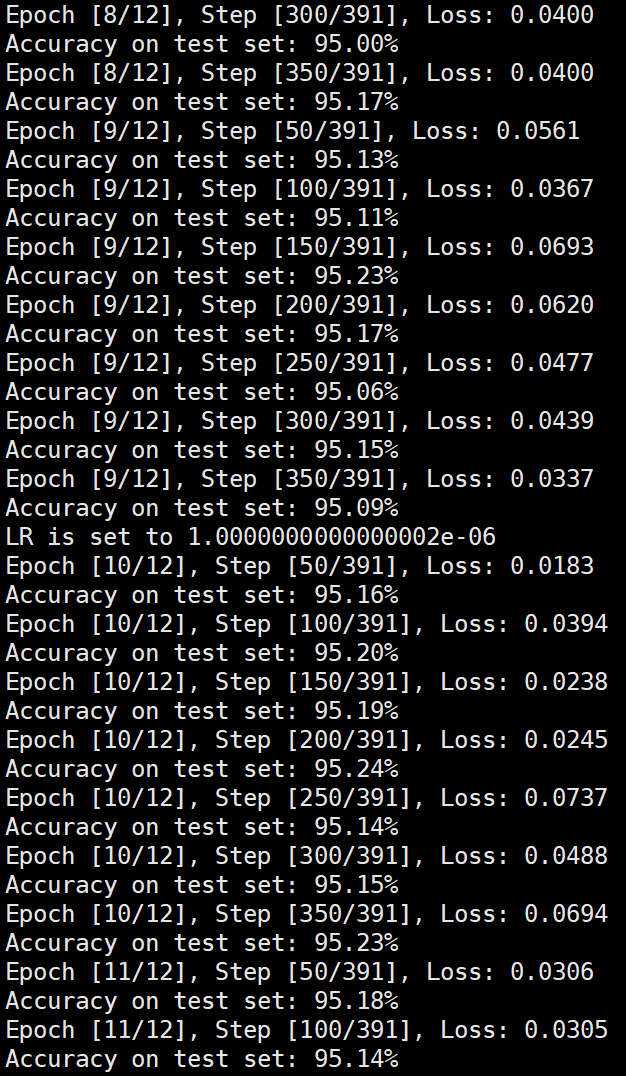
Batchsize:128 epoch:12 lr_decay_epoch:3 初始学习率为0.001 95.23%
Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为0.01 85.87% 和分析的一致,对比下面实验,控制变量,只有初始学习率改变,精度提升10%左右。
Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为0.001 95.44%
Batchsize:64 epoch:20 lr_decay_epoch:5 初始学习率为0.001 95.66%
使用LeNet网络 与Resnet相比换了一个网络和改了数据加载模块,其他没啥变化。
库函数导入 1 2 3 4 5 6 7 8 9 import matplotlib.pyplot as pltimport torchimport torch.nn as nnimport torchvisionimport torchvision.transforms as transformsfrom sklearn.metrics import confusion_matrix, classification_reportfrom itertools import chainimport multiprocessingdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" )
数据集加载及增强操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 transform = transforms.Compose( [transforms.RandomHorizontalFlip(), transforms.RandomCrop(32 , padding=4 ), transforms.ToTensor(), transforms.Normalize((0.5 , 0.5 , 0.5 ), (0.5 , 0.5 , 0.5 ))]) trainset = torchvision.datasets.CIFAR10(root='./data' , train=True , download=True , transform=transform) train_loader = torch.utils.data.DataLoader(trainset, batch_size=32 , shuffle=True , num_workers=2 ) testset = torchvision.datasets.CIFAR10(root='./data' , train=False , download=True , transform=transform) test_loader = torch.utils.data.DataLoader(testset, batch_size=32 , shuffle=False , num_workers=2 ) classes = ('plane' , 'car' , 'bird' , 'cat' , 'deer' , 'dog' , 'frog' , 'horse' , 'ship' , 'truck' ) def output_label (label ): output_mapping = { 0 : "plane" , 1 : "car" , 2 : "bird" , 3 : "cat" , 4 : "deer" , 5 : "dog" , 6 : "frog" , 7 : "horse" , 8 : "ship" , 9 : "truck" } input = (label.item() if type (label) == torch.Tensor else label) return output_mapping[input ]
LeNet模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 class C1 (nn.Module): def __init__ (self ): super (C1, self ).__init__() self .c1 = nn.Sequential(OrderedDict([ ('conv1' , nn.Conv2d(3 , 6 , kernel_size=(5 , 5 ))), ('relu1' , nn.ReLU()), ('pool1' , nn.MaxPool2d(kernel_size=(2 , 2 ), stride=2 )) ])) def forward (self, img ): output = self .c1(img) return output class C3 (nn.Module): def __init__ (self ): super (C3, self ).__init__() self .c3 = nn.Sequential(OrderedDict([ ('conv3' , nn.Conv2d(6 , 16 , kernel_size=(5 , 5 ))), ('relu3' , nn.ReLU()), ('pool3' , nn.MaxPool2d(kernel_size=(2 , 2 ), stride=2 )) ])) def forward (self, img ): output = self .c3(img) return output class F4 (nn.Module): def __init__ (self ): super (F4, self ).__init__() self .f4 = nn.Sequential(OrderedDict([ ('fc4' , nn.Linear(16 * 5 * 5 , 120 )), ('relu4' , nn.ReLU()) ])) def forward (self, img ): output = self .f4(img) return output class F5 (nn.Module): def __init__ (self ): super (F5, self ).__init__() self .f5 = nn.Sequential(OrderedDict([ ('fc5' , nn.Linear(120 , 84 )), ('relu5' , nn.ReLU()) ])) def forward (self, img ): output = self .f5(img) return output class F6 (nn.Module): def __init__ (self ): super (F6, self ).__init__() self .f6 = nn.Sequential(OrderedDict([ ('fc6' , nn.Linear(84 , 10 )) ])) def forward (self, img ): output = self .f6(img) return output class LeNet5 (nn.Module): def __init__ (self ): super (LeNet5, self ).__init__() self .c1 = C1() self .c3 = C3() self .f4 = F4() self .f5 = F5() self .f6 = F6() def forward (self, img ): output = self .c1(img) output = self .c3(output) output = output.view(-1 , 16 * 5 * 5 ) output = self .f4(output) output = self .f5(output) output = self .f6(output) return output
模型训练超参数设置 1 2 3 4 5 6 7 8 9 10 11 12 13 criterion = nn.CrossEntropyLoss() learning_rate = 0.001 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) def exp_lr_scheduler (optimizer, epoch, init_lr=0.001 , lr_decay_epoch=2 ): lr = init_lr * (0.1 ** (epoch // lr_decay_epoch)) if epoch % lr_decay_epoch == 0 : print (f'LR is set to {lr} ' ) for param_group in optimizer.param_groups: param_group['lr' ] = lr return optimizer
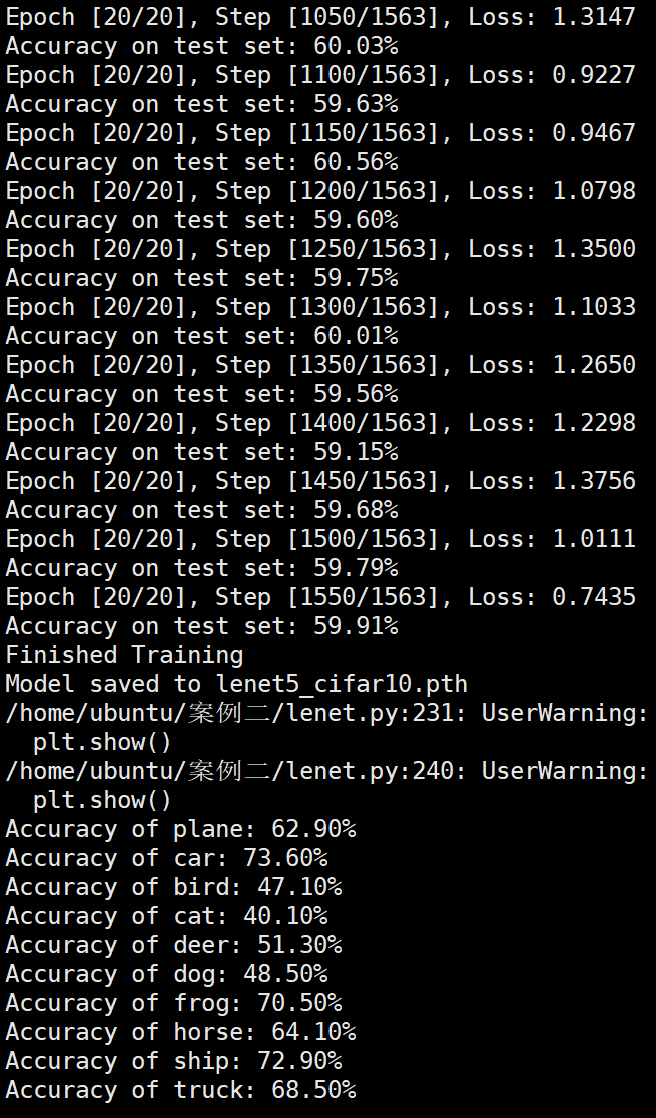
模型训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 num_epochs = 20 count = 0 loss_list = [] iteration_list = [] accuracy_list = [] predictions_list = [] labels_list = [] for epoch in range (num_epochs): model.train() running_loss = 0.0 optimizer = exp_lr_scheduler(optimizer, epoch, init_lr=learning_rate, lr_decay_epoch=2 ) for i, (images, labels) in enumerate (train_loader): images, labels = images.to(device), labels.to(device) outputs = model(images) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() count += 1 if (i + 1 ) % 50 == 0 : print (f'Epoch [{epoch + 1 } /{num_epochs} ], Step [{i + 1 } /{len (train_loader)} ], Loss: {loss.item():.4 f} ' ) model.eval () total = 0 correct = 0 test_predictions = [] test_labels = [] with torch.no_grad(): for images, labels in test_loader: images, labels = images.to(device), labels.to(device) test_labels.extend(labels.cpu().numpy()) outputs = model(images) _, predicted = torch.max (outputs.data, 1 ) test_predictions.extend(predicted.cpu().numpy()) total += labels.size(0 ) correct += (predicted == labels).sum ().item() accuracy = 100 * correct / total print (f'Accuracy on test set: {accuracy:.2 f} %' ) loss_list.append(loss.item()) iteration_list.append(count) accuracy_list.append(accuracy) predictions_list.append(test_predictions) labels_list.append(test_labels) model.train() print ('Finished Training' )
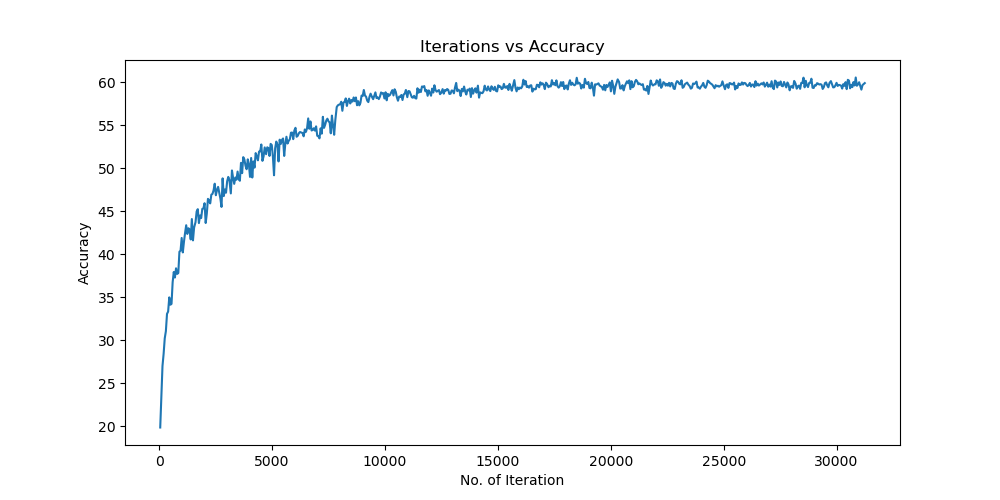
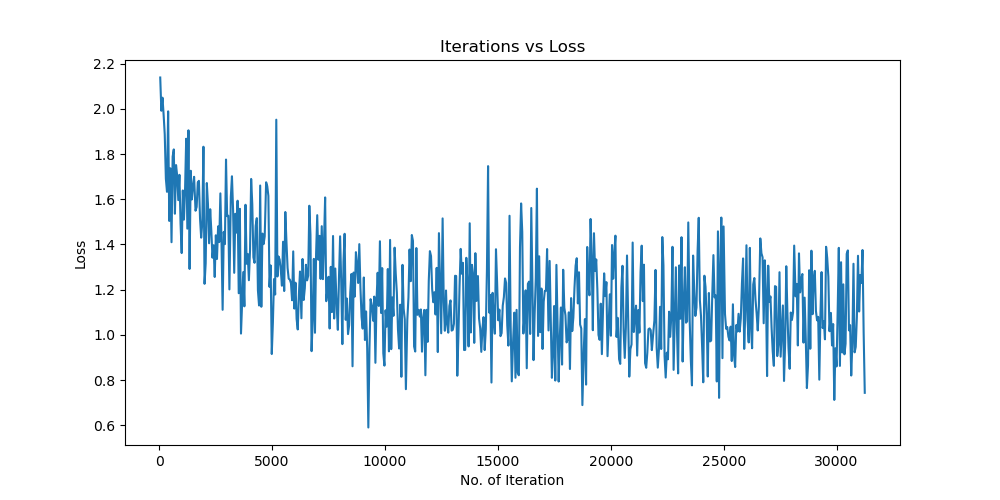
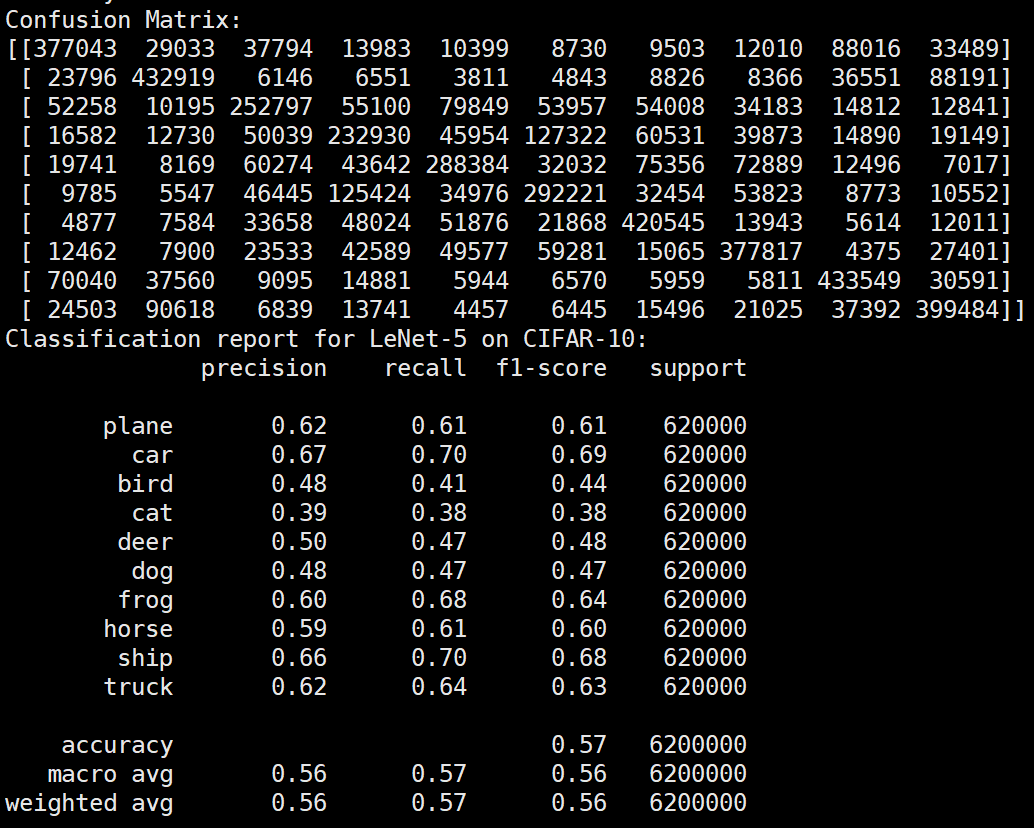
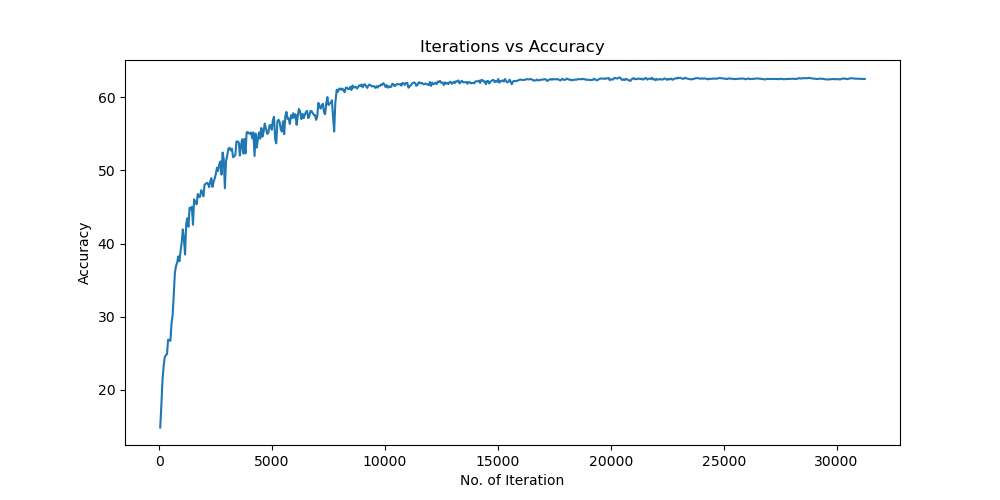
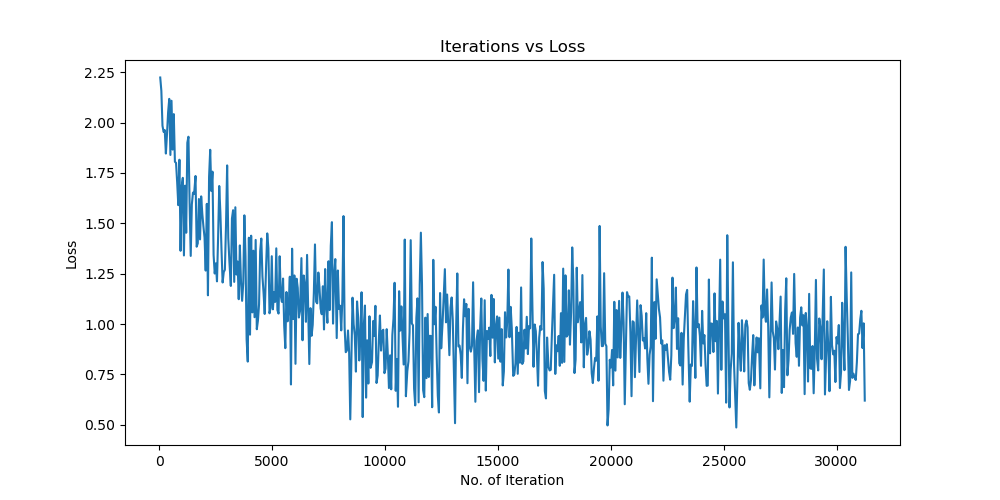
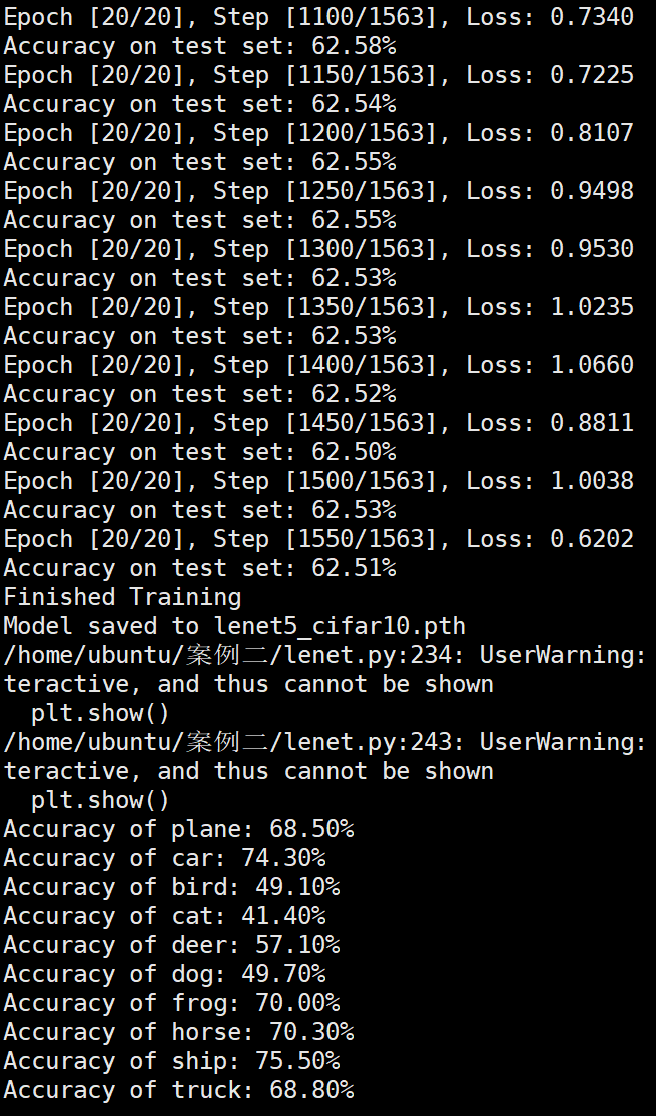
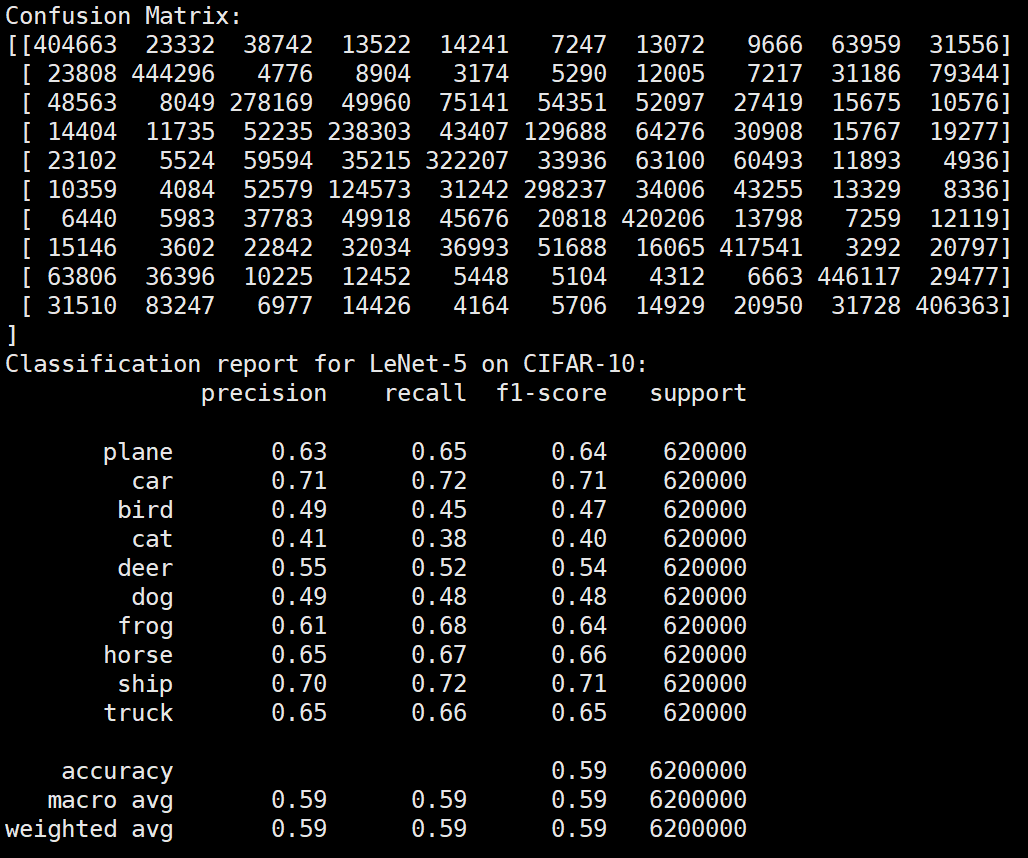
实验结果保存 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 torch.save(model.state_dict(), 'lenet5_cifar10.pth' ) print ('Model saved to lenet5_cifar10.pth' )plt.figure(figsize=(10 , 5 )) plt.plot(iteration_list, loss_list) plt.xlabel("No. of Iteration" ) plt.ylabel("Loss" ) plt.title("Iterations vs Loss" ) plt.savefig('loss_curve.png' ) plt.show() plt.figure(figsize=(10 , 5 )) plt.plot(iteration_list, accuracy_list) plt.xlabel("No. of Iteration" ) plt.ylabel("Accuracy" ) plt.title("Iterations vs Accuracy" ) plt.savefig('accuracy_curve.png' ) plt.show() class_correct = [0. for _ in range (10 )] total_correct = [0. for _ in range (10 )] model.eval () with torch.no_grad(): for images, labels in test_loader: images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max (outputs, 1 ) c = (predicted == labels).squeeze() for i in range (labels.size(0 )): label = labels[i] class_correct[label] += c[i].item() total_correct[label] += 1 for i in range (10 ): print (f"Accuracy of {classes[i]} : {100 * class_correct[i] / total_correct[i]:.2 f} %" ) flat_predictions = list (chain.from_iterable(predictions_list)) flat_labels = list (chain.from_iterable(labels_list)) cm = confusion_matrix(flat_labels, flat_predictions) print ("Confusion Matrix:" )print (cm)print ("Classification report for LeNet on CIFAR-10:" ) print (classification_report(flat_labels, flat_predictions, target_names=classes))
实验结果分析 使用图像增强操作 Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 60.56%
未使用图像增强操作 Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 62.66%
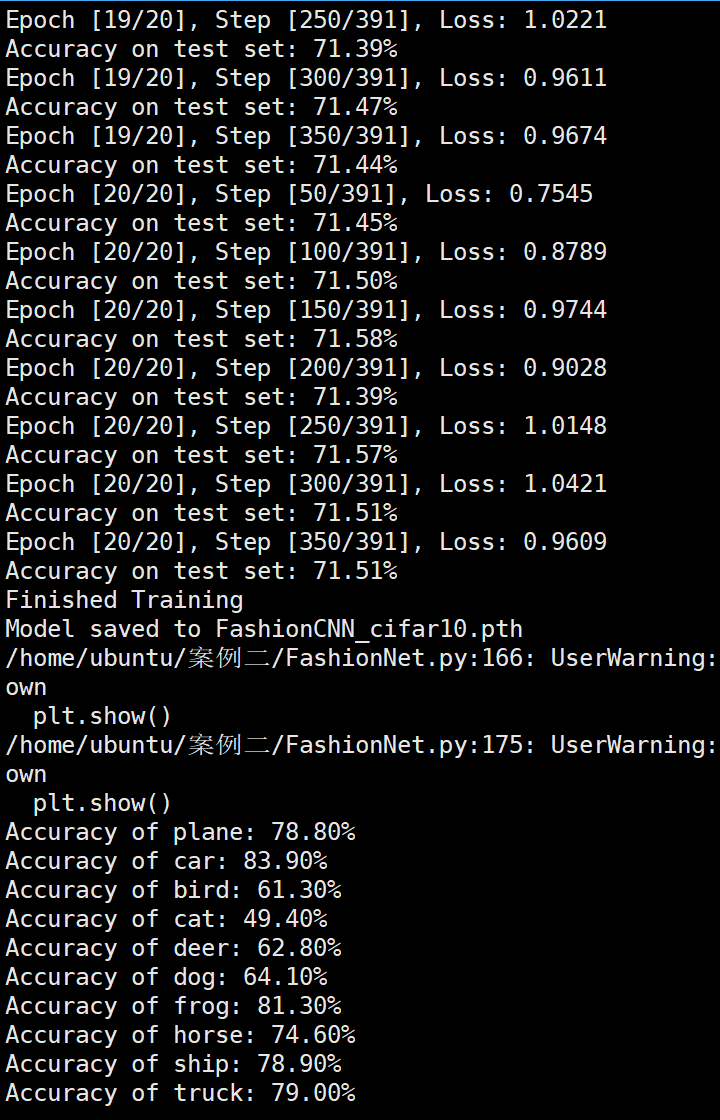
使用FashionNet 代码详见github
图像增强操作训练结果分析 使用图像增强操作 Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 71.51% 未使用图像增强操作 Batchsize:128 epoch:30 lr_decay_epoch:6 初始学习率为 0.01 71.69%
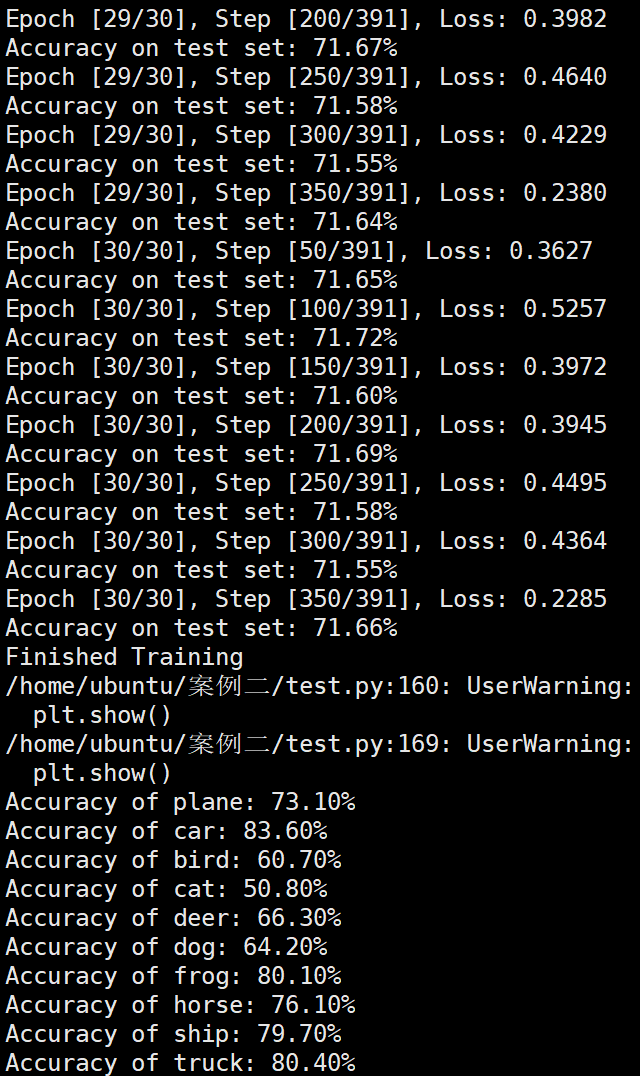
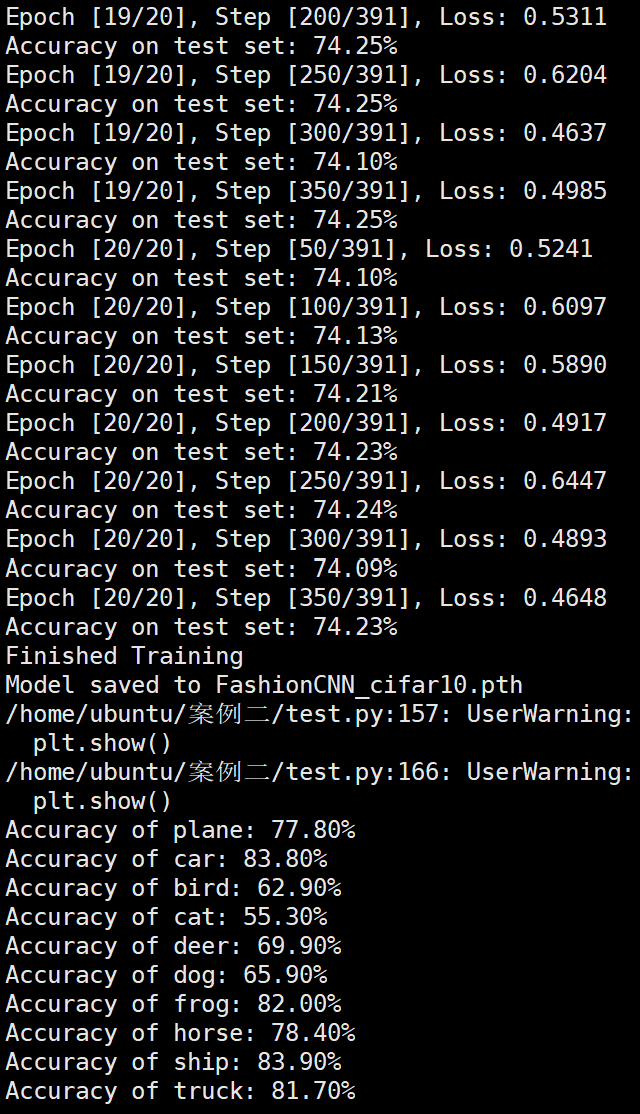
Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 74.25%
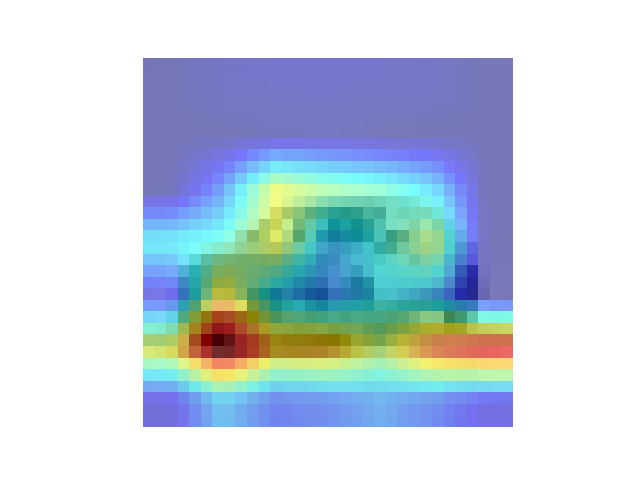
Gradcam实现图像特征可视化 Grad-CAM 的目标层均为最后一个卷积层
Resnet效果图 参数配置 Batch_size:64 epoch:20 lr_decay_epoch:5 lr:0.001 95.66%
图片来自谷歌。
FashionNet效果图 参数配置 Bachsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 74.25%
LeNet效果图 参数配置 Bachsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 60.56%
总结 数据集在不同模型上的准确率 模型 准确率 ResNet 95.66% LeNet 62.66% FashionNet 74.25%
LeNet对数据集进行图像增强操作的影响 分析:由于模型过于简单,本来就会出现欠拟合现象,继续进行图像增强操作后会导致模型更加欠拟合。所以出现三个模型精度差距较大,主要是因为模型复杂度的差距。虽然是欠拟合,但是继续增加epoch也并不会提高精度,因为模型对数据已经学到了尽可能多的知识。
未归一化 归一化 图像增强操作 大量图像增强操作 58.75% 62.66% 60.56% 56.78%
神经网络参数对模型准确率的影响 batch_size:64或128并无太大影响。
初始学习率:由实验结果可得lr=0.01时,效果较差,三个网络都使用了0.01进行测试得出的结果,有的实验结果没贴图。所以直接设置初始学习率为0.001可以更节省时间,提高效率。当学习率为1e-6时,发现准确率更新较小,所以准确率最小设置为1e-6。即学习率梯度为1e-3,1e-4,1e-5,1e-6,可以有较好的效果。
lr_decay_epoch和epoch:即学习率梯度为1e-3,1e-4,1e-5,1e-6,可以有较好的效果。即令epoch / lr_decay_epoch = 3或4 都可以,具体以epoch大小为准。








 微信
微信