CSRMS
用于视觉表征学习的类级结构化关系建模与平滑 (MM2023)
论文地址:https://ercdm.sdu.edu.cn/__local/7/AC/70/7E4948C4761839F62E3958CE772_043AE854_2B459A.pdf
代码地址:https://github.com/czt117/CSRMS
个人理解这个像是一个知识总结的过程。首先通过特征提取获得特征图,这个过程可以类比我从书本上学习知识的过程,提取出有用的知识,然后通过聚类算法对特征图进行分簇,就相当于把学到的知识进行总结的过程,但是总会有一些比较相近的知识容易被搞混,这个就是类间相似性和类内多样性,再着重对这一块进行处理,使得对知识的掌握更加透彻。
名词解释:
课程构建(Curriculum Construction):是一种渐进式学习方法,通过根据任务或样本的难度或复杂性来设计学习顺序,让模型从简单的内容逐步过渡到复杂的内容,从而更高效地掌握知识。它通过评估样本难度、调整学习权重并动态控制训练过程,帮助模型更高效地学习,最终提高收敛速度和泛化能力。
实例级别的图像(Instance-level images):指的是针对单个具体图像样本的研究和处理。每一张图像被视为一个独立的实例,拥有其独特的特征和属性,而不是仅仅代表某个类别或群体的共性。与类别级别(Class-level)的研究不同,实例级别更关注图像的个体差异和细节。
对比学习(Contrastive Learning):是一种机器学习技术,特别在无监督学习和自监督学习中应用广泛。它的核心思想是通过对比不同样本之间的相似性和差异性,让模型自动学习数据的特征表示
研究目的
缓解类内多样性和类间相似性问题
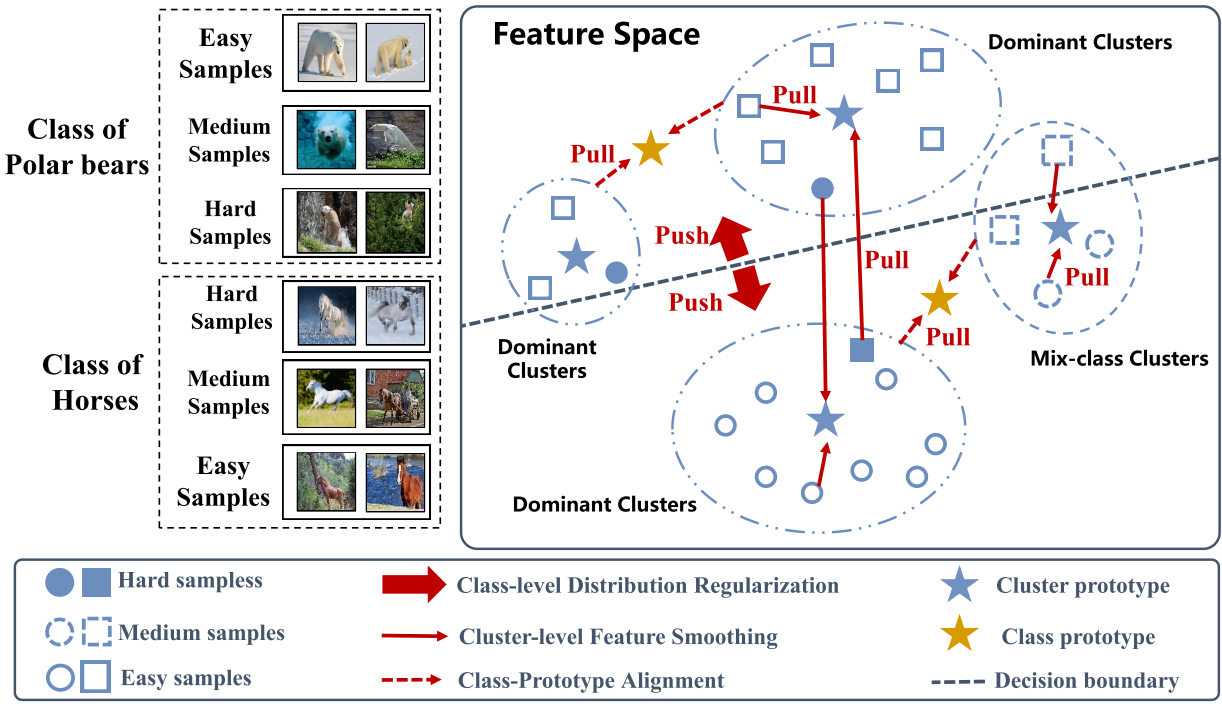
整体架构
CSRMS 框架的三个核心模块:类级关系建模、类感知图采样 和 关系图引导的表示学习
在离线学习阶段,根据表征视觉分布挖掘类级关系,构建数据集级关系图;在训练阶段,根据类级关系构建多样化类感知采样策略,结合课程构建,获得Batch级别关系子图;在类级关系的引导下,利用特征平滑、类原型对齐和类级约束显式正则化视觉表征,有效缓解视觉表征分布复杂性。
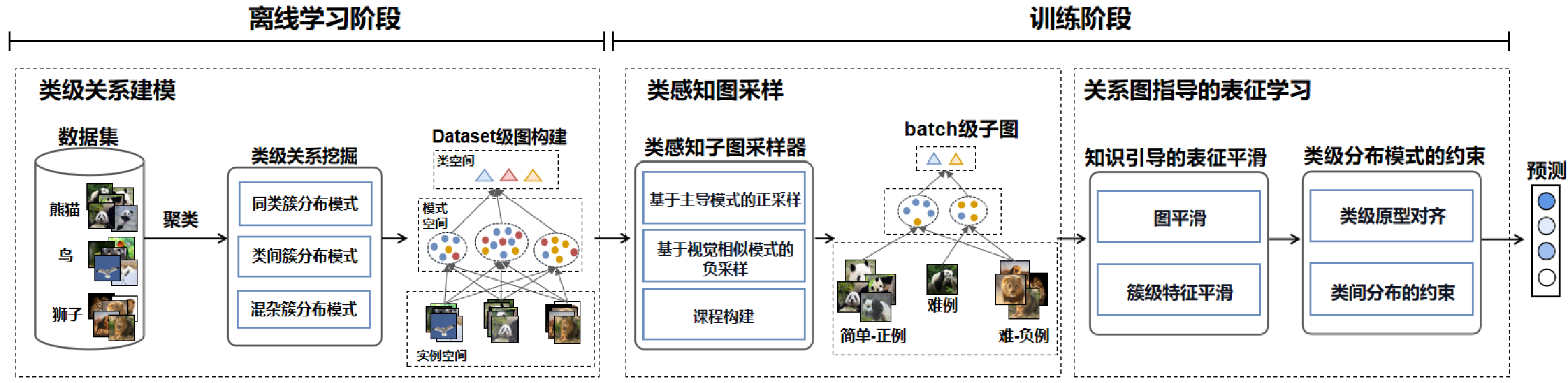
离线学习阶段
类级关系建模
类级关系定义
(a) 类内视觉模式的多样性(Intra-Class Diversity of Visual Patterns):同一类别的样本分布在不同主导簇,说明类内样本视觉差异大。
$$
R_{ID} = \{ (I_a, I_b) \mid y_a = y_b, P_{C_a} \neq P_{C_b} \}
$$
(b) 视觉模式的类间相似性 (Inter-Class Similarity of Visual Patterns):不同类别的样本分布在同一主导簇,说明类间样本视觉上相似。
$$
R_{IS} = \{(I_a, I_b) \mid y_a \neq y_b, P_{C_a} = P_{C_b} \}
$$
© 视觉模式的混类簇 (Mix-class Cluster of Visual Patterns):不同类别的样本分布在同一混类簇,说明聚类结果复杂,缺乏主导类别。
$$
R_{MC} = \{(I_a, I_b) \mid y_a \neq y_b, M_{C_a} = M_{C_b} \}
$$
主导簇(Dominant Clusters):指聚类中主要由某个类别样本构成的簇,通常通过聚类算法基于特征分布确定。
混类簇(Mix-class Clusters):指聚类中没有明显主导类别的簇,包含多个类别的样本,增加了建模难度。
ART聚类
自适应聚类算法 ART:能够根据数据分布动态调整簇数量,适合处理视觉特征空间中的复杂分布。对视觉特征进行聚类,得到视觉模式。$ C={c1,…,cJ}$
$$
C = ART(M_v(I))
$$
得到三个级别:类级别、模式级别、实例级别。然后构建关系图 $G_t$ 。这是一个多层图结构,实例级别连接到模式级别(通过聚类),模式级别连接到类级别(通过标签),这种结构有助于捕捉样本间的复杂关系。
训练阶段
类感知图采样
正样本采样
使用主导模式采样器$ S_{dp} $,从类别 $ y_i $ 主导的最大簇 $c_j $ 中选择与 $ I_i $ 距离最大的前 $ n $个正样本。为每个批次样本选择正样本集合 $ \Omega_{posi} $,以解决类内多样性。
选择距离最远的正样本,增加类内样本的多样性,增强表征学习的鲁棒性。
$$
\Omega_{posi} = S_{dp}(I_i, \varphi(I_i, I_{i_j}), n)
$$
负样本采样
视觉相似模式采样器 $ S_{ap} $,从类别 $ y_i $ 主导的最大簇 $c_i $ 中选择与 $ I_i $ 距离最大的前 $m$个正样本。为每个批次样本选择负样本集合$\Omega_{nega} $,以解决类间相似性和混类簇。
选择视觉相似的负样本,增强类间区分度,缓解类间相似性问题。
$$
\Omega_{nega} = S_{ap}(I_i, \varphi(I_i, I_{i_j}), m)
$$
课程学习
基于易难估计,为批次样本分配难度级别。
$$
f(I_i) = \begin{cases}
\Omega_{\text{easy}} & \text{if } \frac{N_k^j}{N_k} > \rho_1 \\
\Omega_{\text{medium}} & \text{if } \frac{N_k^j}{N_k} < \rho_1 \\
\Omega_{\text{hard}} & \text{if } \frac{N_k^h}{N_k} > \rho_1 \text{ and } j \neq h
\end{cases}
$$
调整学习权重
使用“衰减方法”,设置惩罚系数,并通过参数调节。
$$
α_i⋅λ_e+(1−α_i)⋅(α_f⋅λ_m+(1−α_f)⋅λ_h)=1
$$
初期:$\alpha_i $、$ \alpha_f $接近 1,优先学习简单样本。
后期:当损失收敛(例如损失 < 0.01 且连续两轮损失差 < 0.0001)时,逐步减小 $ \alpha_i $、$ \alpha_f $,引入更多困难样本。
构建批次子图
$G_b$ 是 $ G_t $的一个子图,针对每个训练批次(batch)生成,包含批次中的样本及其正负样本对,用于后续表征学习。过采样策略,从 $ G_t $中选择与批次样本相关的子图结构,保留类级别、模式级别和实例级别的关系,同时引入正样本和负样本以增强表征学习。
关系图引导的表示学习
簇感知表征平滑
图形平滑
使用图卷积网络(GCN)$ \mathcal{G}(\cdot) $,基于子图 $ G_b $ 和正样本 $ \Omega_{posi} $,聚合同一类别图像的信息。
$$
F_g=\mathcal{G}(\hat{A},I_i,Ω_{posi})=softmax(\hat{A}⋅ReLU(\hat{A}⋅X⋅W^{(1)})⋅W^{(0)})
$$
簇级特征平滑
将表征 $ F_g $ 与簇原型 $ w_{cu} $ 对齐,其中$w_{cu} $是类别 $ y_i $主导的最大簇 $c_j $的原型。
$$
F_u=α_u⊙F_g+β_u⊙w_{cu}
$$
类级分布正则化
类级表征对齐
表征 $ F_u$ 与类原型 $ p_{cu} $ 对齐,其中 $ p_{cu} $ 是类别 $ y_i $ 在所有主导簇中的表征聚合。
$$
F_a=α_a⊙F_u+β_a⊙p_{cu}
$$
负样本约束
构建负样本损失$\mathcal L_{neg}$,推远不同类别表征:
$$
\mathcal L_{neg} = \sum_{i=1}^{N} -\log \left( \mu_{i} \frac{\theta}{\sum_{q=1}^{m}|M_v(I_i) - M_v(\Omega_{nega}^q)|_2 + \theta} \right)
$$
类间约束
构建类间分散损失$\mathcal L_{inter}$,进一步推远不同类别表征:
$$
\mathcal L_{inter} = \sum_{i,j} { i = j } |0| + { i \ne j } -\log \left( \mu\frac{\theta}{|F_v^i - F_v^j|_2 + \theta} \right)
$$
分类器训练
使用分类器 $ C(\cdot) $预测类别:
$$
F_a →P
$$
使用交叉熵损失 $\mathcal L_{ce}$优化:
$$
\mathcal L_{ce} = \frac{1}{N} \sum_{i} \mathcal L_i = -\frac{1}{N} \sum_{i}\sum_{c=1}^{C} y_{ic} \log(P_{ic})
$$
 微信
微信