MoCo
Momentum Contrast for Unsupervised Visual Representation Learning (cvpr2020)
论文地址:https://arxiv.org/pdf/1911.05722
代码地址:https://github.com/facebookresearch/moco
概述

MoCo 将对比学习看作是一个字典查找任务 :一个编码后的查询(query)应该与其匹配的键(正样本)相似,而与其他所有的键(负样本)不相似 。
对比学习的核心思想是训练一个编码器,使其能够区分相似(正样本)和不相似(负样本)的样本 。
传统方法 VS MoCo
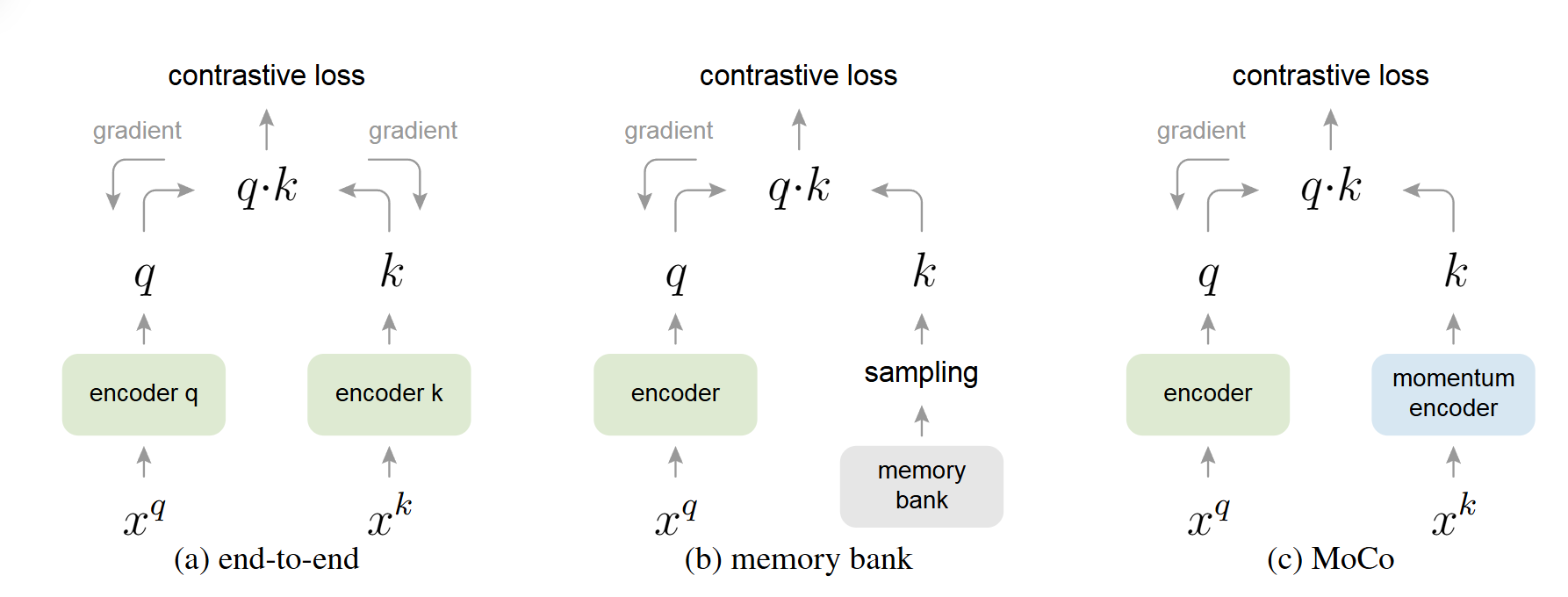
端到端(End-to-end)方法(SimCLR,Inva Spread):将当前 mini-batch 内的样本作为字典 。这种方法的优点是字典中的键编码是一致的(由同一个编码器生成),但缺点是字典的大小受限于 mini-batch 的大小,而 mini-batch 大小又受限于 GPU 内存 。过大的 mini-batch 也会带来优化难题 。
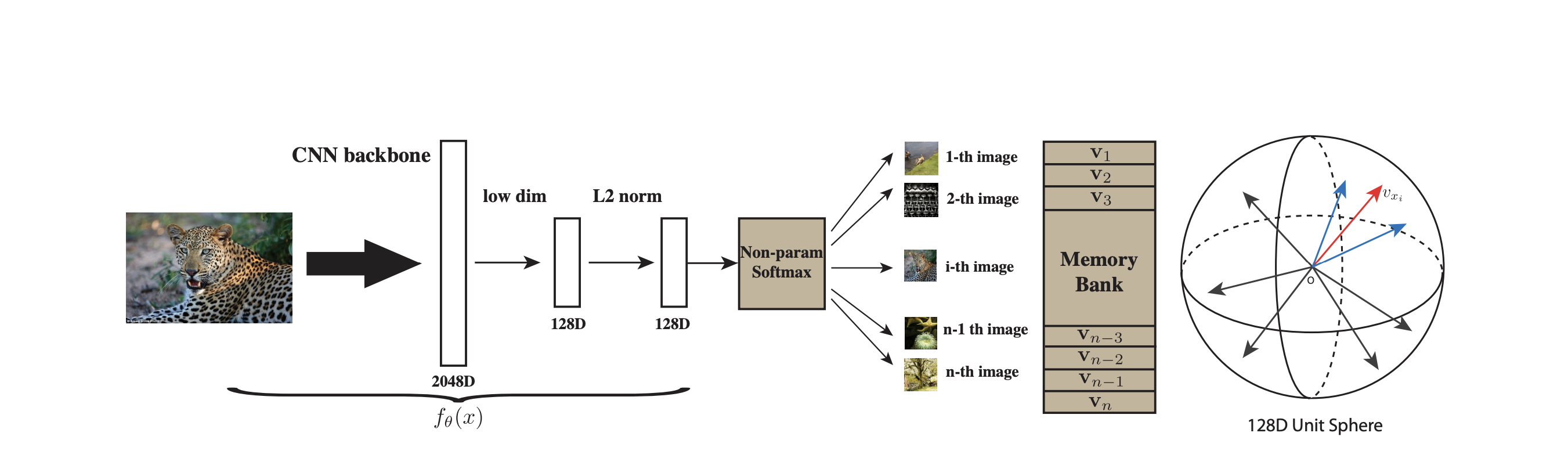
Memory Bank 方法(Inst Disc):Memory Bank包含数据集所有数据的特征表示,从Memory Bank中采样数据不需要进行反向传播,所以能支持比较大的字典,然而一个样本的特征表示只在它出现时才在Memory Bank更新,所以一个epoch只会更新一次,但模型在训练过程中不断迭代,这个特征就会“过时”,因此具有更少的一致性,而且它的更新只是进行特征表示的更新,不涉及encoder。
MoCo跟Inst Disc是非常相似的,比如它用队列取代了原来的memory bank作为一个额外的数据结构去存储负样本,用动量编码器去取代了原来loss里的约束项,这样就可以动量的更新编码器,而不是动量的去更新特征,从而能得到更好的结果。其整体的出发点以及一些实现的细节(比如backbone和lr、batch_size,dim、τ等等超参数都是一样的)和Inst Disc都是非常类似的,所以可以说MoCo是Inst Disc的改进工作。
创新点
MoCo 通过两个创新点解决了这一问题:基于队列的动态字典和动量编码器,给无监督的对比学习构造了一个又大又一致的字典。
基于队列的动态字典
MoCo 使用一个队列来存储图像表征(称为键),作为动态字典。通过这种“先进先出”的更新方式,队列始终保持固定的大小,并且包含的是相对较新的样本表示,有助于维持字典的一致性。队列可以容纳 65,536 个键,为对比学习提供了丰富的负样本集合。
1 | f_k.params = f_q.params # 初始化 |
动量编码器
MoCo 使用两个编码器:查询编码器(query encoder)和键编码器(key encoder)。查询编码器通过反向传播正常更新,而键编码器是查询编码器的缓慢更新版本,其参数通过动量机制更新。具体来说,键编码器的参数是其之前参数与查询编码器参数的加权平均,动量系数(momentum coefficient)通常设为 0.999,使得键编码器变化非常缓慢。这种稳定性保证了队列中键的表征不会因编码器快速变化而失去一致性。
$$
\theta_k \leftarrow m \theta_k + (1-m) \theta_q
$$
query的编码器和key的编码器既可以是相同的(模型的架构一样,参数完全共享,比如Inva Spread),或者说它们的参数是部分共享的,也可以是彻底不一样的两个网络(CMC,多视角多编码器)。
Pretext Task(代理任务)
论文中主要采用了一个简单的实例判别任务(Instance Discrimination):如果一个查询和一个键来源于同一张图片的不同随机增强视图(例如,不同的裁剪、颜色抖动等),则它们构成一个正样本对;否则构成负样本对 。编码器(如 ResNet )将这些视图编码为特征向量,然后通过 InfoNCE 损失函数进行优化 。
损失函数
在对比学习中,最常用的目标函数是 InfoNCE 损失(Noise-Contrastive Estimation 的信息理论扩展)。InfoNCE 损失基于互信息最大化的思想,鼓励模型区分正样本对和负样本对。
$$
\mathcal L_{q} = - \log \frac{\exp(q \cdot k_{+} / \tau)}{\sum_{i=0}^{K} \exp(q \cdot k_{i} / \tau)}
$$
$ q $ 是查询的编码表示。
$ k_{+} $ 是正样本键的编码表示。
$ k_i $ 是字典中所有的键(包括一个正样本 $ k_{+} $ 和 K 个负样本)。
$ \tau $ 是超参数,用来控制分布的形状 ,去掉后整个式子其实就是交叉熵损失函数。
$ q \cdot k $ 表示点积相似度。
NCE loss(noise contrastive estimation ):将超级多分类转为二分类——数据类别data sample和噪声类别noisy sample。这样解决了类别多的问题。
 微信
微信