对比学习综述:从理论到实践全面解析
引言
对比学习(Contrastive Learning) 是近年来自监督学习领域最重要的突破之一,它通过"拉近正样本、推远负样本"的简单思想,在无需大量标注数据的情况下学习到强大的视觉表示。从2020年的SimCLR、MoCo开始,对比学习在ImageNet等基准上取得了与监督学习相当甚至更好的性能,彻底改变了我们对无监督表示学习的认知。
对比学习的核心优势在于:
- 无需标注数据:可以在海量无标注图像上预训练
- 学习鲁棒表示:对数据增强、噪声等具有强鲁棒性
- 迁移能力强:预训练的特征在下游任务上表现优异
- 可扩展性好:可以轻松扩展到大规模数据和模型
什么是对比学习?
核心思想
对比学习的核心思想可以用一句话概括:通过对比正样本对和负样本对,学习到区分性的表示。
正样本对(Positive Pairs):应该相似的样本对
- 无监督:同一图像的不同增强视图
- 有监督:同一类别的不同样本
负样本对(Negative Pairs):应该不相似的样本对
- 无监督:不同图像的增强视图
- 有监督:不同类别的样本
学习目标:让模型学习到的特征空间中,正样本对的距离近,负样本对的距离远。
为什么需要对比学习?
1. 标注数据稀缺问题
- 获取大规模标注数据成本高昂(ImageNet标注花费数百万美元)
- 很多领域缺乏专家标注(医疗、卫星图像等)
- 标注质量难以保证,存在标注噪声
2. 自监督学习的优势
- 利用数据自身的结构作为监督信号
- 可以在海量无标注数据上预训练
- 学习到的特征更通用,迁移性更好
3. 对比学习的独特价值
- 判别性强:通过对比学习到的特征比重建任务(如自编码器)更有判别性
- 计算高效:比生成模型(GAN、VAE)训练更稳定、收敛更快
- 理论基础:有信息论的理论支撑(互信息最大化)
对比学习的工作原理
核心机制详解:
正负样本构造
- 正样本对:同一图像通过不同数据增强得到的两个视图
- 负样本对:来自不同图像的视图
- 关键点:正样本共享语义信息,负样本语义不同
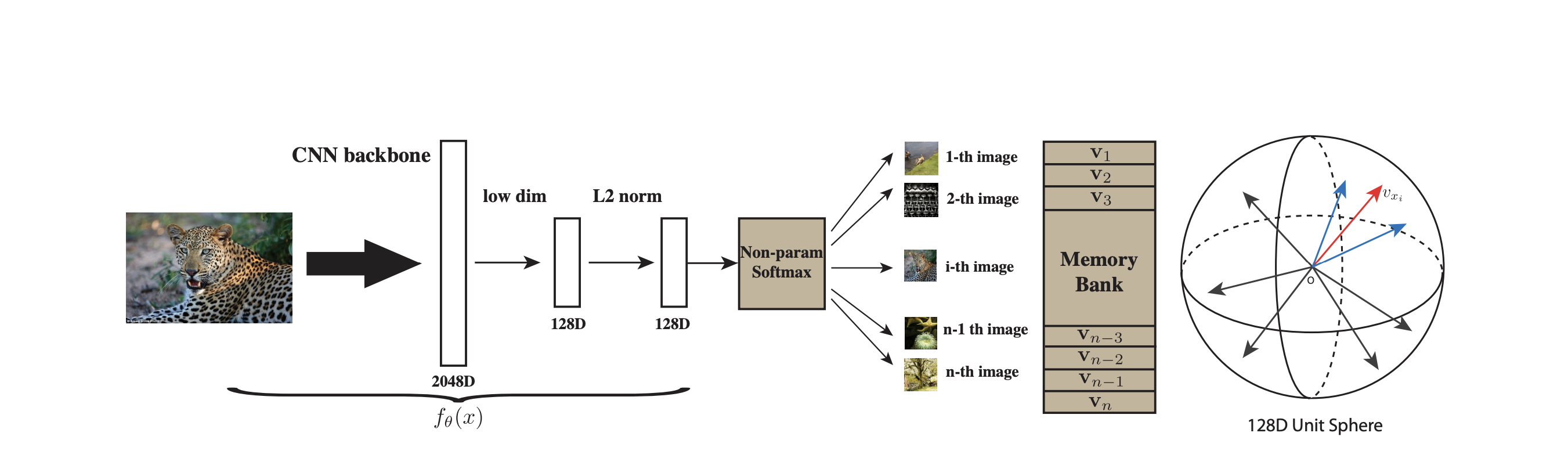
特征提取流程
特征提取流程
1
2
3
4
5
6graph LR
A[输入图像] --> B[数据增强]
B --> C[编码器]
C --> D[特征向量]
D --> E[投影头]
E --> F[对比损失]- 编码器:提取高维语义特征(如ResNet输出2048维)
- 投影头:映射到低维空间(通常128维),便于计算相似度
相似度计算
- 使用余弦相似度:
- 温度缩放:,控制分布的集中程度
优化目标
- 最大化正样本对的相似度
- 最小化负样本对的相似度
- 通过InfoNCE损失实现这一目标
对比学习的发展历程
早期工作(2010s)
- Triplet Loss(2015):最早的形式化对比学习思想
- NCE(Noise Contrastive Estimation):从语言模型引入对比思想
- Instance Discrimination:将每个样本视为一个类别
现代对比学习(2020-)
- SimCLR(2020):端到端训练,大batch size
- MoCo(2020):动量编码器 + 队列机制
- SupCon(2020):监督对比学习
- BYOL/SimSiam(2020-2021):无需负样本的对比学习
- CLIP(2021):跨模态对比学习
核心损失函数:InfoNCE / NT-Xent
InfoNCE损失详解
损失函数定义:
给定一个正样本对和 N-1 个负样本,InfoNCE损失定义为:
:- 计算查询样本与正样本的余弦相似度
- 值域:[-1, 1],1表示完全相同,-1表示完全相反
温度缩放:
- 通常设置为0.07-0.5
- 较小的让模型更关注困难负样本
- 较大的让优化更平滑
Softmax归一化:
- 将相似度转换为概率分布
- 正样本的"概率"应该接近1
- 每个负样本的"概率"应该接近0
负对数似然:
- 最小化损失 = 最大化正样本的概率
- 这等价于N分类问题,正确类别是正样本
为什么InfoNCE有效?
- 归一化:特征先进行L2归一化
- 温度缩放:控制softmax分布的尖锐程度
温度参数的作用
温度参数是对比学习中的关键超参数:
较小(如0.05):
- 分布更尖锐,模型更关注困难负样本
- 学习到的表示区分性更强
- 但可能训练不稳定
较大(如0.2):
- 分布更平滑,对所有样本的关注更均匀
- 训练更稳定
- 但区分性可能较弱
典型取值:0.07(SimCLR、MoCo等常用)
主要方法详解
1. SimCLR(A Simple Framework for Contrastive Learning)
论文:https://arxiv.org/pdf/2002.05709
代码:https://github.com/google-research/simclr
核心思想
SimCLR提出了一个简单而有效的对比学习框架:
- 对每个样本应用两次随机增强,得到两个视图
- 使用共享编码器提取特征
- 通过投影头映射到对比空间
- 使用NT-Xent损失进行对比学习
关键创新
- 强数据增强:发现数据增强是对比学习成功的关键
- 投影头:在编码器和损失之间加入非线性投影头
- 大batch size:需要大量负样本(batch size ≥ 4096)
架构
架构
1 | graph LR |
优缺点
优点:
- 框架简单,易于实现
- 端到端训练,无需额外机制
- 性能优异
缺点:
- 需要大batch size,对计算资源要求高
- 对数据增强策略敏感
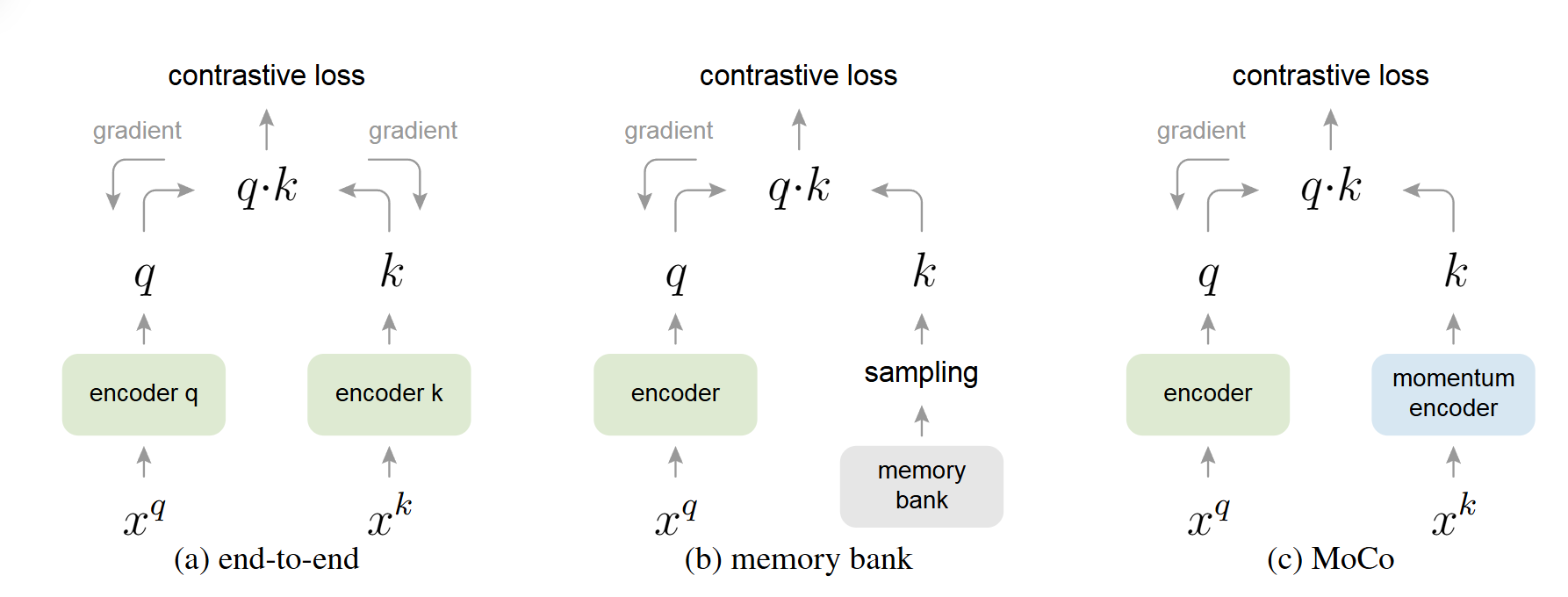
2. MoCo(Momentum Contrast)
论文:https://arxiv.org/pdf/1911.05722
代码:https://github.com/facebookresearch/moco
核心思想
MoCo将对比学习看作字典查找任务:
- Query:当前样本的编码
- Key:字典中的样本编码
- 目标:Query与匹配的Key相似,与其他Key不相似
关键创新
- 动量编码器:使用动量更新维护一个缓慢变化的编码器
- 队列机制:用队列存储历史样本的特征,提供大量负样本
- 一致性:动量更新保证字典中Key的一致性
架构
架构
1 | graph LR |
优缺点
优点:
- 不依赖大batch size
- 训练稳定,收敛快
- 内存效率高
缺点:
- 实现相对复杂
- 需要维护队列和动量编码器
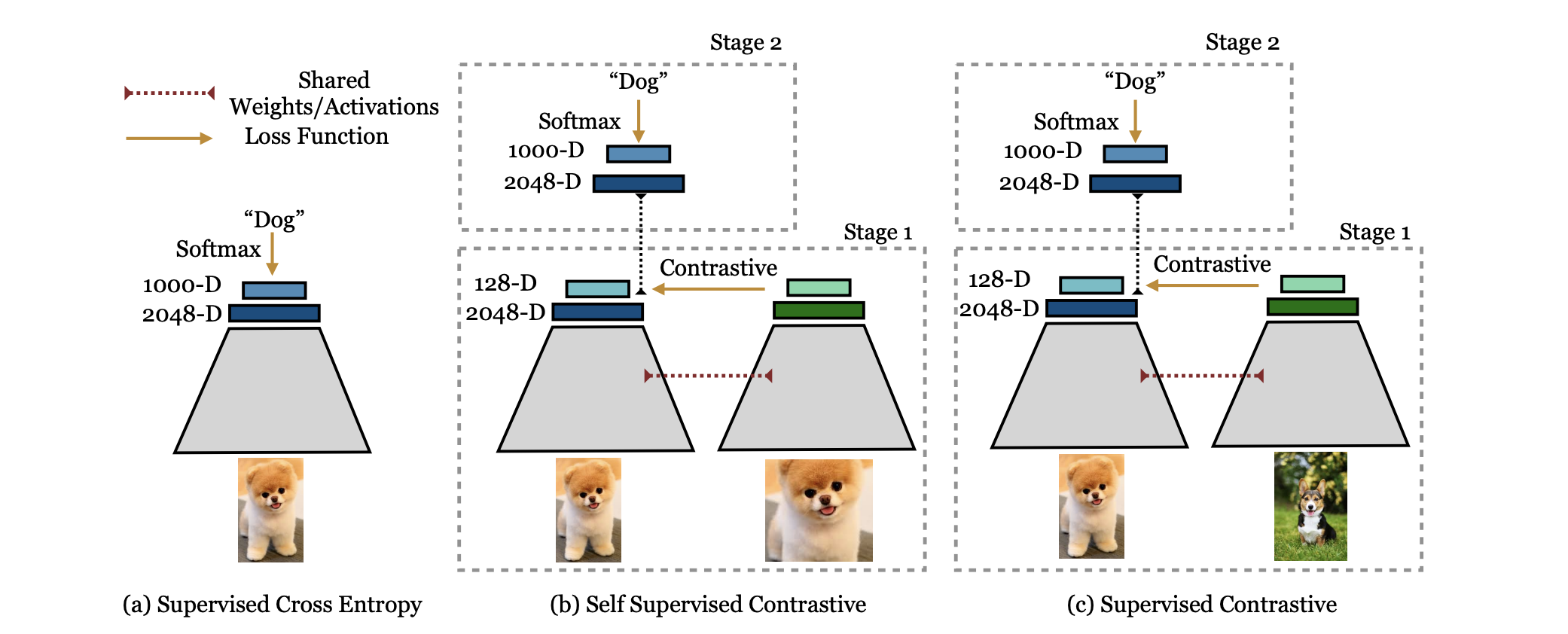
3. SupCon(Supervised Contrastive Learning)
论文:https://arxiv.org/pdf/2004.11362
代码:https://github.com/HobbitLong/SupContrast
核心思想
将标签信息融入对比学习:
- 正样本:同一类别的所有样本
- 负样本:不同类别的样本
损失函数
\mathcal{L}{sup}^i = -\frac{1}{|P(i)|} \sum{p \in P(i)} \log \frac{\exp(z_i \cdot z_p / \tau)}{\sum_{a \in A(i)} \exp(z_i \cdot z_a / \tau)}
$$
其中是与样本同类的样本集合。
优缺点
优点:
- 利用标签信息,性能更优
- 鲁棒性显著提升
- 在长尾学习、少样本学习上表现优异
缺点:
- 需要标注数据
- 计算复杂度较高()
4. BYOL / SimSiam(无需负样本)
BYOL论文:https://arxiv.org/pdf/2006.07733
SimSiam论文:https://arxiv.org/pdf/2011.10566
核心思想
通过预测任务替代对比任务,无需负样本:
- 一个视图预测另一个视图
- 使用停止梯度(stop-gradient)防止崩溃
关键机制
- 预测头:预测一个视图的特征
- 停止梯度:防止模型学习到平凡解(所有特征相同)
- 对称损失:同时优化两个方向
优缺点
优点:
- 无需负样本,计算更高效
- 训练更稳定
缺点:
- 理论理解仍在发展中
- 性能可能略低于有负样本的方法
5. SwAV (Swapping Assignments between Views)
论文:https://arxiv.org/pdf/2006.09882
代码:https://github.com/facebookresearch/swav
核心思想
SwAV 将对比学习与聚类相结合。它不直接对比两个视图的特征,而是对比它们在聚类中心的分配(Assignment)。
- 核心假设:同一图像的两个视图应该属于同一个聚类中心。
- 机制:用一个视图的特征去预测另一个视图的聚类分配。
架构
1 | graph LR |
优缺点
- 优点:无需大量负样本,无需大batch size,训练效率高。
- 缺点:需要在线聚类,实现稍复杂。
6. CLIP (Contrastive Language-Image Pre-training)
论文:https://arxiv.org/pdf/2103.00020
代码:https://github.com/openai/CLIP
核心思想
将对比学习扩展到多模态领域。使用海量的(图像,文本)对进行训练。
- 正样本:匹配的(图像,文本)对。
- 负样本:不匹配的(图像,文本)对。
架构
1 | graph LR |
影响
CLIP 的出现标志着对比学习从单纯的视觉表示学习走向了通用的多模态理解,为后来的 DALL-E、Stable Diffusion 等生成模型奠定了基础。
技术细节与实践指南
数据增强策略详解
核心增强技术:
随机裁剪(RandomResizedCrop)
- 最重要的增强,强制模型学习局部-整体关系
- 参数:scale=(0.08, 1.0),ratio=(0.75, 1.33)
- 作用:模拟不同视角和距离
颜色抖动(ColorJitter)
- 调整亮度、对比度、饱和度、色相
- 参数:brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1
- 作用:学习颜色不变的特征
高斯模糊(GaussianBlur)
- SimCLR发现这是关键增强之一
- 参数:kernel_size=图像宽度的1/10,sigma=[0.1, 2.0]
- 作用:强制关注高层语义而非纹理细节
随机灰度化(RandomGrayscale)
- 概率:通常设为0.2
- 作用:学习不依赖颜色的形状特征
增强组合的重要性:
1 | # SimCLR推荐的增强pipeline |
投影头设计原理
为什么需要投影头?
信息瓶颈作用
- 编码器输出包含丰富信息(2048维)
- 投影到低维(128维)强制提取关键信息
- 防止模型记住无关细节
任务分离
- 编码器学习通用表示(用于下游任务)
- 投影头学习对比特定表示(训练后丢弃)
- 保护编码器特征不被对比任务"污染"
实验发现
- 无投影头:下游任务性能下降约10%
- 线性投影头:有改善但不够
- 非线性投影头(2层MLP):最佳性能
投影头架构:
1 | # 典型的投影头设计 |
训练技巧
学习率:
- 大batch size时使用大学习率(如0.3)
- 使用LARS优化器(大batch)或AdamW
学习率调度:
- Cosine annealing
- Warmup(10%的训练步数)
Batch Size:
- SimCLR:≥ 4096
- MoCo:256-1024即可
- SupCon:根据类别数调整
训练时长:
- 通常需要较长的训练(100-1000 epochs)
- 使用更多数据可以缩短训练时间
特征归一化
为什么需要归一化?
- 控制特征尺度,避免某些维度 dominate
- 使余弦相似度计算有意义
- 提高训练稳定性
归一化方式:
1 | z = F.normalize(features, p=2, dim=1) # L2归一化 |
代码实现
InfoNCE损失实现
1 | import torch |
完整的对比学习训练示例
1 | import torch |
应用场景
1. 图像分类
- 预训练:在ImageNet等大规模数据集上预训练
- 微调:在下游分类任务上微调编码器
- 性能:可以达到或超越监督预训练的性能
2. 目标检测
- Backbone预训练:使用对比学习预训练检测器的backbone
- 迁移学习:将预训练特征迁移到检测任务
- 性能提升:显著提升检测精度,特别是少样本场景
3. 语义分割
- 特征提取器预训练:预训练分割网络的特征提取部分
- 少样本分割:在少样本分割任务上表现优异
4. 图像检索
- 特征学习:学习到适合检索的判别性特征
- 相似度计算:直接使用学习到的特征进行检索
5. 长尾学习
- SupCon优势:监督对比学习在长尾分布上表现优异
- 类间分离:显式推远异类样本,提高尾部类别性能
对比学习 vs 其他方法
vs. 监督学习
| 特性 | 监督学习 | 对比学习 |
|---|---|---|
| 数据需求 | 需要大量标注 | 无需标注 |
| 表示质量 | 任务相关 | 通用性强 |
| 鲁棒性 | 一般 | 更强 |
| 计算成本 | 较低 | 较高(大batch) |
vs. 生成式方法(VAE、GAN)
| 特性 | 生成式方法 | 对比学习 |
|---|---|---|
| 目标 | 重建/生成 | 表示学习 |
| 训练稳定性 | 不稳定 | 较稳定 |
| 表示质量 | 可能包含无关信息 | 更聚焦判别性 |
| 计算效率 | 较低 | 较高 |
vs. 自编码器
| 特性 | 自编码器 | 对比学习 |
|---|---|---|
| 目标 | 重建输入 | 区分样本 |
| 表示性质 | 可能包含冗余 | 更紧凑 |
| 下游任务 | 需要额外设计 | 直接可用 |
扩展领域:NLP中的对比学习
对比学习不仅在CV领域大放异彩,在NLP领域也同样重要。
SimCSE (Simple Contrastive Learning of Sentence Embeddings)
论文:https://arxiv.org/pdf/2104.08821
核心思想:
- 无监督 SimCSE:利用 Dropout 作为数据增强。将同一个句子输入预训练模型(如BERT)两次,由于 Dropout 的存在,得到两个略有不同的 embedding,作为正样本对。
- 有监督 SimCSE:利用 NLI 数据集中的(蕴含,前提)作为正样本,(矛盾,前提)作为负样本。
影响:SimCSE 极大地提升了句向量的质量,成为 NLP 句向量表示的标准基线。
前沿探讨:对比学习 vs 掩码图像建模 (MIM)
随着 MAE (Masked Autoencoders) 和 BEiT 的提出,视觉预训练领域出现了新的范式竞争。
掩码图像建模 (MIM)
- 代表作:MAE, BEiT, SimMIM
- 核心思想:类似 BERT,遮挡图像的一部分 patch,让模型重建被遮挡的像素或特征。
- 优势:
- 训练效率高(只需处理可见 patch)。
- 学习到的特征包含更多细节信息,利于检测和分割任务。
- 扩展性极强(Scaling Law)。
对比学习 (CL) vs MIM
| 特性 | 对比学习 (CL) | 掩码图像建模 (MIM) |
|---|---|---|
| 核心目标 | 区分样本 (全局语义) | 重建细节 (局部关系) |
| 数据增强 | 极其依赖 (强增强) | 不太依赖 (仅需 Mask) |
| 特征性质 | 线性可分性好,适合分类 | 细节丰富,适合定位/分割 |
| 训练效率 | 较低 (需处理全图) | 较高 (仅处理部分) |
| 当前趋势 | 多模态对齐 (CLIP) | 视觉基础模型 (ViT Pretraining) |
结论:两者并非对立,正在趋于融合(如 IBOT, EVA 等工作尝试结合两者的优势)。
当前挑战与解决方案
主要技术挑战
1. 大批次训练的硬件需求
问题:
- SimCLR需要4096-8192的batch size才能达到最佳性能
- 需要多GPU训练,单GPU难以实现
解决方案:
- MoCo方法:使用队列存储负样本,减少GPU内存需求
- 梯度累积:多次前向传播累积梯度,模拟大batch
- 混合精度训练:使用FP16减少内存使用
2. 负样本的质量问题
问题:
- 随机采样的负样本可能包含语义相似的样本(假负样本)
- 简单负样本提供的学习信号有限
解决方案:
- 困难负样本挖掘:选择相似度较高的负样本
- 去偏采样:使用先验知识避免假负样本
- 自适应温度:动态调整温度参数关注困难样本
3. 数据增强的设计
问题:
- 不同任务需要不同的增强策略
- 过强增强可能破坏语义信息
解决方案:
- AutoAugment:自动搜索最优增强策略
- 任务特定增强:根据下游任务设计增强
- 增强强度调度:训练过程中逐渐增强强度
常见问题与调试
1. 模型崩溃(所有样本映射到同一点)
症状:损失快速下降到0,所有特征相同
解决:
- 检查是否有stop-gradient操作
- 确保使用了负样本
- 添加正则化项
2. 性能不提升
可能原因:
- Batch size太小(< 256)
- 温度参数设置不当
- 数据增强太弱或太强
调试步骤:
- 可视化增强后的图像,确保保留语义
- 监控正负样本相似度分布
- 尝试不同的温度参数(0.05-0.5)
3. 下游任务性能差
原因分析:
- 预训练与下游任务domain gap
- 使用了投影头的特征而非编码器特征
- 预训练不充分
改进方法:
- 在目标domain数据上预训练
- 使用编码器特征进行下游任务
- 增加预训练epochs
总结
对比学习通过"拉近正样本、推远负样本"的简单思想,在无需大量标注数据的情况下学习到强大的视觉表示。从SimCLR、MoCo到SupCon,对比学习的方法不断演进,性能不断提升。
关键要点:
- 数据增强是关键:强数据增强是对比学习成功的重要因素
- 负样本数量很重要:需要足够的负样本才能学到好的表示
- 温度参数需要调优:对性能有重要影响
- 投影头很重要:在编码器和损失之间加入投影头能提升性能
- 可以结合监督信号:SupCon证明了标签信息可以进一步提升性能
对比学习的成功证明了无监督表示学习的巨大潜力,为未来的研究指明了方向。
参考文献
Chen, T., et al. (2020). A Simple Framework for Contrastive Learning of Visual Representations. ICML 2020. https://arxiv.org/pdf/2002.05709
He, K., et al. (2020). Momentum Contrast for Unsupervised Visual Representation Learning. CVPR 2020. https://arxiv.org/pdf/1911.05722
Khosla, P., et al. (2020). Supervised Contrastive Learning. NeurIPS 2020. https://arxiv.org/pdf/2004.11362
Grill, J. B., et al. (2020). Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. NeurIPS 2020. https://arxiv.org/pdf/2006.07733
Chen, X., & He, K. (2021). Exploring Simple Siamese Representation Learning. CVPR 2021. https://arxiv.org/pdf/2011.10566
Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. ICML 2021. https://arxiv.org/pdf/2103.00020
思考题
- 为什么对比学习需要大量的负样本?负样本数量如何影响学习效果?
- 温度参数的物理意义是什么?如何根据任务选择合适的?
- 数据增强在对比学习中的作用是什么?为什么某些增强(如crop)比其他增强更重要?
- MoCo的动量编码器和队列机制是如何解决SimCLR的大batch size问题的?
- 监督对比学习(SupCon)相比无监督对比学习(SimCLR/MoCo)的优势和劣势是什么?
- 为什么BYOL和SimSiam可以在没有负样本的情况下工作?停止梯度机制的作用是什么?
思考题答案
1. 为什么对比学习需要大量的负样本?负样本数量如何影响学习效果?
为什么需要大量负样本?
- 提供对比信号:负样本提供了"什么不应该相似"的信息,帮助模型学习区分性
- 防止崩溃:足够的负样本防止模型学习到平凡解(所有特征相同)
- 提高表示质量:更多负样本意味着更丰富的对比信号,学习到的表示更具判别性
负样本数量的影响:
- 太少(< 64):对比信号不足,模型难以学习到好的表示
- 适中(256-4096):性能随负样本数量增加而提升
- 太多(> 8192):收益递减,计算成本显著增加
实验发现:
- SimCLR:batch size从256增加到8192,性能持续提升
- MoCo:队列大小从128增加到65536,性能提升但收益递减
2. 温度参数的物理意义是什么?如何根据任务选择合适的?
物理意义:
温度参数控制softmax分布的尖锐程度(entropy):
- :分布接近one-hot,模型只关注最相似的样本
- :分布接近均匀,模型对所有样本的关注相等
数学上:是softmax中的缩放因子,影响梯度的尺度
选择策略:
- 起始值:0.07(SimCLR、MoCo等常用)
- 任务特性:
- 细粒度分类(类别相似)→ 较小的(0.05)
- 粗粒度分类(类别差异大)→ 较大的(0.1-0.15)
- 观察训练:
- 损失下降快但验证性能差 → 降低
- 训练不稳定 → 提高
- 网格搜索:在[0.05, 0.07, 0.1, 0.15, 0.2]范围内搜索
3. 数据增强在对比学习中的作用是什么?为什么某些增强(如crop)比其他增强更重要?
数据增强的作用:
- 构造正样本对:通过增强同一图像得到不同的视图,作为正样本
- 提高鲁棒性:学习对增强不变的表示,提高泛化能力
- 增加数据多样性:在有限数据上模拟更多场景
为什么crop最重要?
- 语义保持:crop保留了图像的主要语义内容
- 视角变化:模拟了不同的观察视角,是自然的变化
- 空间不变性:帮助模型学习空间不变的特征
增强的重要性排序(SimCLR实验):
- RandomResizedCrop(最重要)
- RandomHorizontalFlip
- ColorJitter
- RandomGrayscale
- GaussianBlur
组合效应:多个增强的组合效果 > 单个增强的简单叠加
4. MoCo的动量编码器和队列机制是如何解决SimCLR的大batch size问题的?
SimCLR的问题:
- 需要大batch size(≥ 4096)提供足够负样本
- 对GPU内存和计算资源要求高
MoCo的解决方案:
队列机制:
- 维护一个FIFO队列存储历史样本的特征
- 队列大小可以很大(如65536),远超batch size
- 每次用新batch的特征替换最旧的队列元素
动量编码器:
- Key编码器通过动量更新:
- 保证队列中Key的一致性(不会因为编码器快速变化而失效)
- 动量系数通常为0.999
优势:
- 不需要大batch size(256-1024即可)
- 队列提供大量且一致的负样本
- 内存效率高(只存储特征,不存储图像)
5. 监督对比学习(SupCon)相比无监督对比学习(SimCLR/MoCo)的优势和劣势是什么?
优势:
- 正样本更明确:同类样本作为正样本,比增强视图更可靠
- 性能更优:在分类任务上通常超越无监督方法
- 鲁棒性更强:对对抗样本、噪声等更鲁棒
- 长尾学习:在类别不平衡数据上表现优异
- 少样本学习:学习到的表示泛化能力更强
劣势:
- 需要标注数据:无法利用无标注数据
- 计算成本高:需要计算所有样本对的相似度()
- 任务相关:学习到的表示可能更偏向特定任务
- 类别依赖:需要知道类别信息,限制了应用场景
适用场景:
- SupCon:有标注数据,关注分类性能和鲁棒性
- 无监督:无标注数据,需要通用表示
6. 为什么BYOL和SimSiam可以在没有负样本的情况下工作?停止梯度机制的作用是什么?
为什么可以工作?
- 预测任务替代对比:通过预测一个视图的特征来学习表示
- 对称损失:同时优化两个方向的预测
- 停止梯度:防止模型学习到平凡解
停止梯度机制:
在BYOL/SimSiam中,一个分支的梯度被停止:
1 | # SimSiam示例 |
作用:
- 防止崩溃:如果没有停止梯度,两个分支可能学习到相同的表示(平凡解)
- 非对称性:创造非对称的学习信号,使模型必须学习有意义的表示
- 稳定训练:避免两个分支相互"追逐",训练更稳定
理论理解:
- 停止梯度创造了一个"教师-学生"的关系
- 一个分支作为"教师"提供目标,另一个作为"学生"学习
- 这种非对称性防止了表示空间的坍塌
深度思考与实践经验
- 对比信号的本质:无论是SimCLR还是MoCo,本质上都在重建一个“相似样本的局部图结构”。从这个角度看,数据增强、负样本采样、温度参数都是在调节局部图的形状。实践中可以通过构建邻接矩阵或最近邻图来检查模型学习到的结构是否符合预期。
- 大batch与动量编码器的权衡:SimCLR依赖大batch,MoCo依赖动量编码器与队列。前者更适合TPU或多节点GPU环境,后者对资源要求更低但需要额外调节动量系数。在工业部署时,可根据硬件与延迟要求选择不同方案。
- Projection Head的价值:许多工程实践表明,只要下游任务不是k-NN检索,就应当保留投影头并在微调时丢弃。投影头相当于一个“噪声抑制器”,把与对比任务高度相关但与下游任务无关的因素隔离开。
- 数据增强的语义边界:对比学习依赖“语义不变”的增强。如果增强破坏了语义一致性(例如在细粒度识别中使用过强的随机裁剪),模型可能误学到错误关联。设计增强时应结合业务常识:什么变化对用户看来仍是同一对象?
- InfoNCE作为下界:InfoNCE提供了互信息的可计算下界。下界松紧程度受负样本数量、温度、特征容量、优化状态影响。若训练良好却仍觉得效果不足,可以尝试提高下界(更多负样本、更低温度)或改用其他目标(如Barlow Twins、VICReg)。
开放问题
- 困难负样本自动发现:目前多靠随机采样,能否结合难例挖掘或生成模型来构建更具区分度的负样本?
- 跨模态对比的统一框架:CLIP等方法表明文本-图像对比极具潜力,是否存在统一的对比学习范式涵盖视觉、语言、音频?
- 长序列与视频:视频对比学习如何解决时间维度的冗余与语义错配问题?现有工作(VideoMAE、TimeSformer)仍在探索。
- 理论上界与可解释性:对比学习能否提供误差上界或泛化保证?如何解释实例判别自动聚类的现象?
- 增量与联邦场景:当数据分布随时间变化或分散在不同客户端时,如何稳定地维护对比学习的记忆(队列/Memory Bank)?
 微信
微信