最近有一些问题,正好记录下来了一些,用AI探讨了一下这些问题。
1. 残差 (Residual) 的本质:仅仅是保留原始信息吗?
问题: 残差的本质是什么?为什么有用?是因为保留了之前的原始信息的特征吗?那么添加动量 (Momentum) 也是保留之前的原始信息,和残差的本质有什么区别吗?
残差连接 (Skip Connection)
残差网络 (ResNet) 的核心公式是 $y = F(x) + x$。
确实,从直观上看,$+x$ 这一项直接将上一层的原始信息“保留”并传递到了下一层。这使得网络在初始化阶段即使 $F(x)$ 接近于 0,整个网络也近似于一个恒等映射 (Identity Mapping),梯度可以无损地反向传播。
本质区别:
- 残差 (ResNet) 解决的是 模型结构 (Model Architecture) 和 梯度流 (Gradient Flow) 的问题。它是在空间/层级维度上,让深层网络更容易训练,避免梯度消失。它让网络“有机会”去学习恒等映射,如果某一层是多余的,网络可以将 $F(x)$ 权重置为 0,自动“跳过”这一层。
- 动量 (Momentum) 解决的是 优化算法 (Optimization) 的问题。它是在时间/迭代维度上,利用历史梯度的加权平均来平滑优化路径。它保留的是“之前的更新方向”,而不是“之前的特征图”。动量帮助优化器冲出局部极小值,加速收敛。
总结: 残差保留的是特征信息(为了更好训练深层网络),动量保留的是梯度惯性(为了更快收敛)。两者作用的维度完全不同。
2. MAE 中 Mask 的作用:仅仅是加噪声吗?
问题: MAE (Masked Autoencoders) 中遮住图片块的作用是什么?可以用到我的项目中吗?
回答:
MAE 中遮住 75% 甚至更多的图片块,确实可以被视为一种极端的数据增强 (Data Augmentation) 或 去噪 (Denoising) 任务。
- 本质: 它的核心目的不仅仅是防止过拟合,而是强迫模型去学习图像的 全局语义上下文 (Global Semantic Context)。如果只遮住 10%,模型可以通过插值等局部纹理信息轻松复原;但遮住 75%,模型必须“理解”画面——“这里是一只狗的尾巴,那么左边大概率是狗的身体”,这种推理需要高层的语义理解。
- 缺点: 正如你所说,训练非常慢,需要大量的计算资源和数据量才能收敛出好的特征。
- 能否用于你的项目:
- 能用: 如果你的任务是自监督预训练 (Self-supervised Pre-training),且有大量无标签数据,MAE 是非常好的特征提取器。
- 慎用: 如果你的数据集很小,或者直接在监督任务中作为一种 Augmentation 手段(即输入 Mask 后的图直接做分类),效果可能适得其反,因为丢失了太多信息。
启示: 找经典论文中的方法,要看它解决的根本矛盾是什么。MAE 解决的是 Vision Transformer 如何高效利用无标签数据进行预训练的问题。
3. 特征维度:越高越好吗?
问题: 特征维度越高会不会表征能力越强呢?
回答:
理论上,高维空间能容纳更复杂的信息,但这有一个边际效应递减甚至负面效应的问题:
- 维度灾难 (Curse of Dimensionality): 随着维度增加,数据在空间中会变得极度稀疏。为了填满高维空间,所需的数据量是指数级增长的。如果数据量不够,高维特征极易导致过拟合。
- 流形假设 (Manifold Hypothesis): 真实世界的图像虽然像素维度很高(如 224x224x3),但它们通常分布在一个低维的流形上。我们希望模型学到的是这个“低维流形”的坐标,而不是简单地把维度撑大。
- 计算冗余: 过高的维度带来巨大的计算和存储开销。
结论: 维度不是越高越好,而是**“足够表达且紧凑”**最好。通常在 ResNet50 中 2048 维已经非常丰富,很多轻量级模型 512 维甚至 128 维也能达到很好的效果。
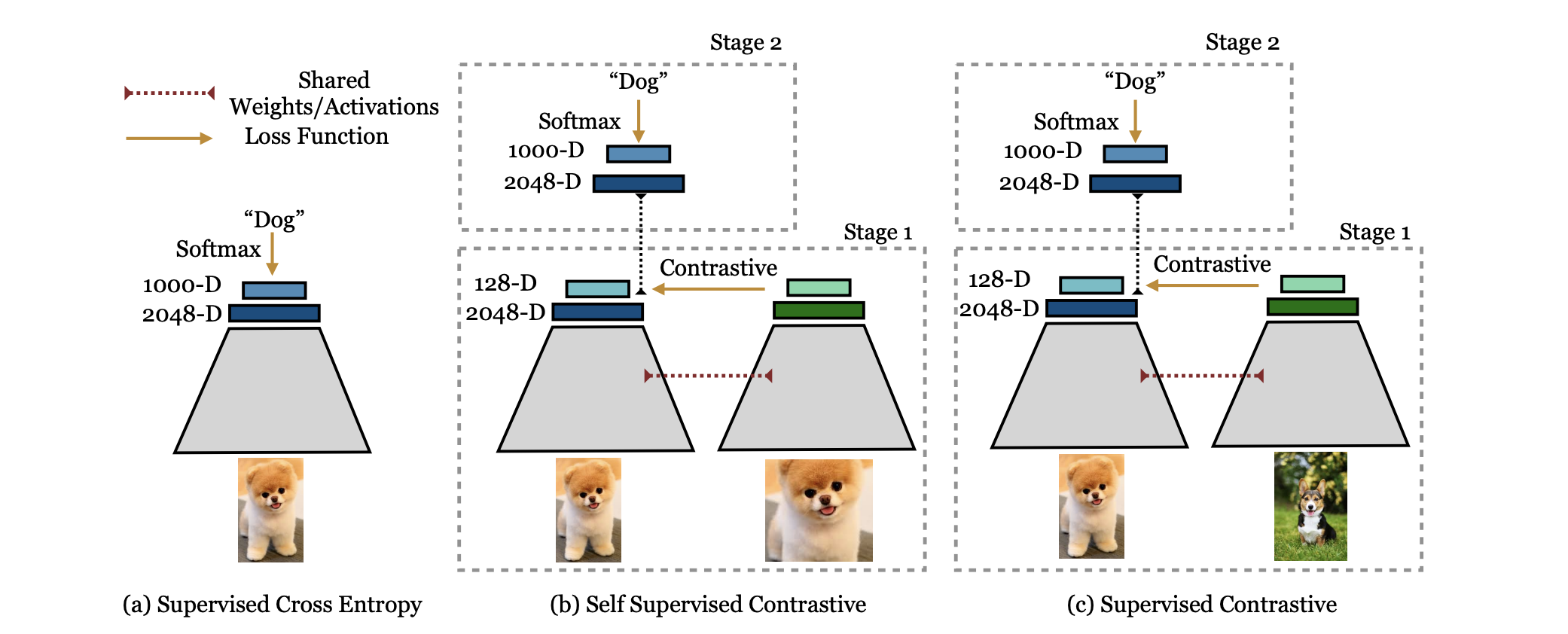
4. 编码器后的 MLP (Projection Head):神来之笔?
问题: 在编码器后边加一个单独的 MLP 层为什么会起作用,数学原理是什么?我在我的算法后边加入 Non-linear 试一下。
回答:
这在对比学习(如 SimCLR, BYOL)中非常常见。
- 现象: 训练时加上 MLP (Projection Head) 计算 Loss,但在下游任务(如分类)时去掉 MLP,直接用 Encoder 的输出,效果反而更好。
- 原理 (Information Bottleneck):
- 对比学习的目标是让增强后的两个视图特征尽可能一致(Invariant)。
- 但是,数据增强(如裁剪、变色)会引入一些与物体类别无关的变换信息。
- MLP 的作用是作为一个“缓冲区”或“过滤器”。它负责去适应这些变换(吸收掉与下游任务无关的增强信息),从而保护 Encoder 学到的特征保持纯粹的语义不变性。
- 如果直接用 Encoder 输出算 Loss,Encoder 就被迫去拟合这些变换,导致特征中混入了噪音。
建议: 在你的算法后加入 Non-linear Projection Head (Linear -> ReLU -> Linear) 绝对值得一试!特别是在做特征对齐、对比学习或度量学习的任务中,这往往能带来几个点的提升。
思考总结:
深度学习的很多“黑魔法”,背后往往对应着对信息流、梯度流或优化曲面的某种直觉性的修正。多问几个“为什么”,尝试用不同的视角(如信息论、优化理论)去解释,是进阶的关键。
 微信
微信