Supervised Contrastive Learning
论文地址:https://arxiv.org/pdf/2004.11362
代码地址:https://github.com/HobbitLong/SupContrast
引言
监督对比学习(Supervised Contrastive Learning, SupCon) 是2020年提出的一种结合监督学习和对比学习优势的深度学习方法。与传统的交叉熵损失相比,SupCon通过显式地拉近同类样本、推远异类样本,在图像分类、鲁棒性学习等任务上取得了显著提升。
为什么需要监督对比学习?
传统交叉熵损失的局限:
只关注分类边界
- 交叉熵只要求正确分类,不关心特征空间的结构
- 导致同类样本在特征空间可能很分散
- 决策边界可能过于接近某些样本
忽略类间关系
- 将所有错误分类同等对待
- "猫被分类为狗"和"猫被分类为汽车"的惩罚相同
- 无法利用类别间的语义相似性
对噪声标签敏感
- 错误标签直接影响分类边界
- 难以从噪声中恢复
监督对比学习的优势:
更好的特征空间结构
- 同类样本紧密聚集
- 不同类样本明确分离
- 形成清晰的聚类结构
更强的鲁棒性
- 对标签噪声更鲁棒
- 对对抗样本更鲁棒
- 更好的泛化能力
灵活的应用
- 可以自然处理开放集识别
- 支持少样本学习
- 便于增量学习新类别
方法对比
| 特性 | 交叉熵损失 | 监督对比损失 |
|---|---|---|
| 优化目标 | 分类准确率 | 特征空间结构 |
| 类内约束 | 无 | 拉近同类样本 |
| 类间约束 | 间接(通过分类) | 直接推远异类 |
| 特征分布 | 可能分散 | 紧密聚类 |
| 鲁棒性 | 一般 | 更强 |
| 计算复杂度 | O(NC) | O(N²) |
其中N是batch size,C是类别数。
背景知识
对比学习简介
对比学习的核心思想是:通过对比正样本对和负样本对,学习到区分性的表示。
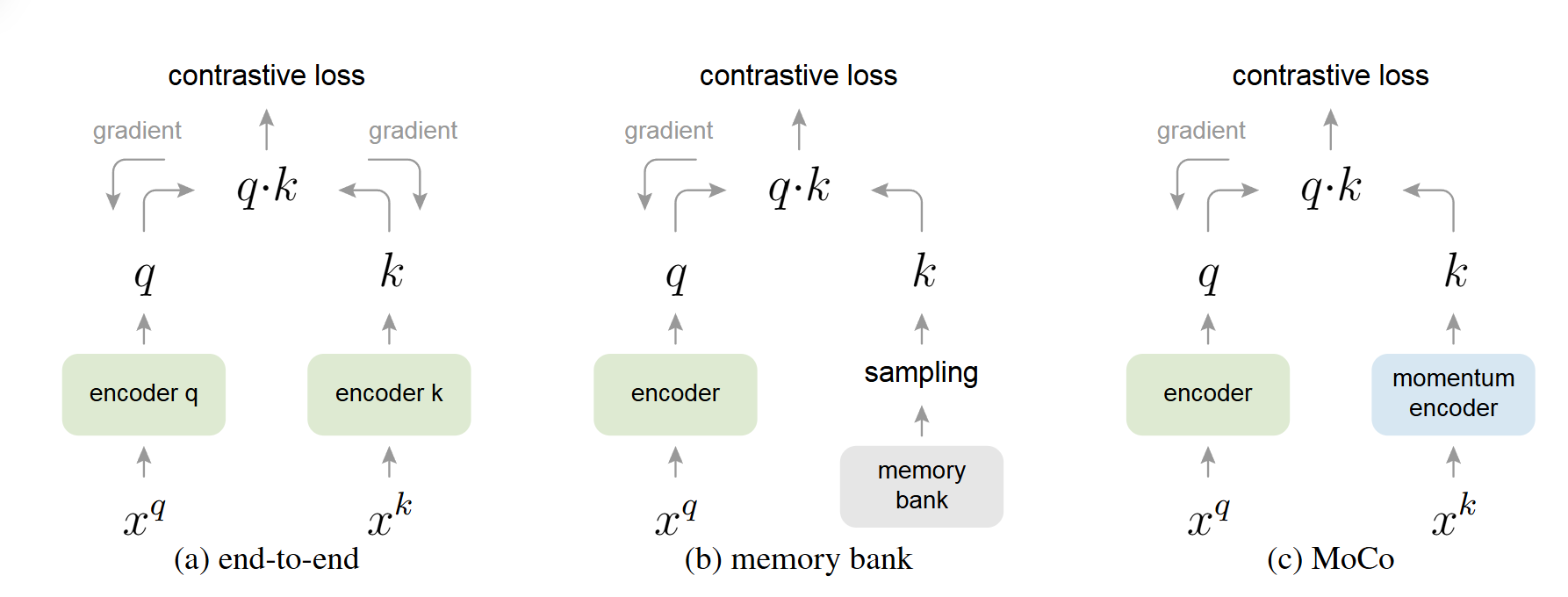
无监督对比学习(如SimCLR、MoCo):
- 正样本:同一图像的不同增强视图
- 负样本:不同图像的增强视图
- 目标:学习到对数据增强不变的表示
关键挑战:
- 需要大量负样本才能学到好的表示
- 对数据增强策略敏感
- 可能学到与下游任务无关的特征
监督学习与对比学习的结合
传统监督学习(交叉熵):
- 只关注样本与标签的匹配
- 忽略了同类样本间的相似性
- 对对抗样本和噪声不够鲁棒
监督对比学习的优势:
- 利用标签信息,正样本对更明确(同类样本)
- 负样本对更丰富(所有异类样本)
- 学习到的表示更具判别性和鲁棒性
论文核心思想
主要贡献
- 提出监督对比损失(Supervised Contrastive Loss):将标签信息融入对比学习框架
- 理论分析:证明了SupCon损失的梯度特性优于交叉熵
- 实验验证:在ImageNet等数据集上取得SOTA性能,并显著提升鲁棒性
核心创新
关键洞察:在监督学习中,同类样本应该聚集在一起,异类样本应该分离。这与对比学习的目标天然一致。
方法:将同一类别的所有样本视为正样本,不同类别的样本视为负样本,构建对比学习目标。
方法原理
监督对比损失(Supervised Contrastive Loss)
给定一个batch的样本及其标签,对每个样本:
$$ \mathcal{L}_{sup} = \sum_{i=1}^{N} \mathcal{L}_{sup}^i $$
其中:
$$ \mathcal{L}_{sup}^i = -\frac{1}{|P(i)|} \sum_{p \in P(i)} \log \frac{\exp(z_i \cdot z_p / \tau)}{\sum_{a \in A(i)} \exp(z_i \cdot z_a / \tau)} $$
符号说明:
- :样本的归一化特征表示
- :与同类的样本集合(正样本)
- :除外的所有样本(正样本+负样本)
- :温度参数,控制分布的尖锐程度
直观理解:
- 分子:拉近同类样本的相似度
- 分母:推远所有样本(包括异类和同类)的相似度
- 归一化:确保同类样本的贡献相等()
与交叉熵损失的对比
交叉熵损失:
$$ \mathcal{L}_{CE} = -\log \frac{\exp(W_{y_i}^T z_i)}{\sum_{j=1}^{C} \exp(W_j^T z_i)} $$
关键区别:
| 特性 | 交叉熵 | 监督对比损失 |
|---|---|---|
| 优化目标 | 样本与分类器权重匹配 | 样本间相似性 |
| 梯度特性 | 只关注当前样本 | 同时考虑所有同类/异类样本 |
| 表示学习 | 间接(通过分类器) | 直接(样本间关系) |
| 鲁棒性 | 较弱 | 更强 |
训练流程
- 数据增强:对每个样本应用两次随机增强,得到两个视图
- 特征提取:使用编码器提取特征
- 归一化:对特征进行L2归一化
- 计算损失:使用监督对比损失
- 反向传播:更新编码器参数
注意:SupCon可以单独使用,也可以与交叉熵损失结合使用。
损失函数详解
温度参数的作用
- 较小:分布更尖锐,模型更关注困难样本
- 较大:分布更平滑,模型对所有样本的关注更均匀
- 典型取值:0.07 或 0.1
梯度分析
SupCon损失的梯度特性:
$$ \frac{\partial \mathcal{L}_{sup}^i}{\partial z_i} = \frac{1}{\tau} \left[ \sum_{p \in P(i)} \frac{z_p}{|P(i)|} - \sum_{a \in A(i)} w_a z_a \right] $$
其中是softmax权重。
关键观察:
- 梯度包含所有同类样本的平均(第一项)
- 梯度包含所有样本的加权平均(第二项)
- 这比交叉熵只关注单个样本-权重匹配更丰富
与InfoNCE的关系
SupCon可以看作监督版本的InfoNCE:
- InfoNCE:正样本是同一图像的不同增强
- SupCon:正样本是同一类别的所有样本
实验分析
数据集
论文在多个数据集上进行了实验:
- ImageNet:大规模图像分类基准
- CIFAR-10/100:小规模图像分类
- STL-10:无监督/半监督学习基准
实验设置
网络架构:
- ResNet-50/200 作为backbone
- 投影头:2层MLP(2048→128)
训练细节:
- 优化器:LARS(ImageNet)或SGD
- 学习率:0.3(ImageNet)或0.1(CIFAR)
- Batch size:1024(ImageNet)或256(CIFAR)
- 温度参数:
- 数据增强:RandomResizedCrop、ColorJitter、RandomHorizontalFlip等
实验结果
ImageNet分类性能:
| 方法 | Top-1 Acc | Top-5 Acc |
|---|---|---|
| Cross-Entropy | 76.5% | 93.1% |
| SupCon | 78.0% | 93.8% |
| SupCon + CE | 78.4% | 94.0% |
鲁棒性提升:
- 对对抗攻击的鲁棒性显著提升
- 对常见数据损坏(噪声、模糊等)的鲁棒性更好
- 在长尾分布数据集上表现更优
消融实验:
- 温度参数:0.07 效果最好
- 投影头维度:128维足够
- 数据增强:重要,但SupCon对增强策略的敏感性低于无监督对比学习
代码实现
PyTorch实现
1 | import torch |
简化版本
1 | def supervised_contrastive_loss(features, labels, temperature=0.07): |
技术细节与优化
数据增强策略
SupCon对数据增强的依赖低于无监督对比学习,但仍需要合理的增强:
推荐增强:
- RandomResizedCrop
- RandomHorizontalFlip
- ColorJitter(适度)
- RandomGrayscale(可选)
避免过度增强:过度增强可能破坏语义信息,反而降低性能。
投影头设计
- 层数:2层MLP通常足够
- 维度:128-256维
- 激活函数:ReLU或GELU
- 归一化:输出层L2归一化
温度参数调优
- 起始值:0.07
- 调优范围:0.05 - 0.2
- 原则:如果模型难以区分困难样本,降低;如果训练不稳定,提高
优缺点分析
优点
- 性能提升:在多个数据集上超越交叉熵损失
- 鲁棒性强:对对抗样本、噪声、数据损坏更鲁棒
- 表示质量高:学习到的特征更具判别性和泛化能力
- 易于实现:损失函数简单,易于集成到现有框架
缺点
- 计算成本:需要计算所有样本对的相似度,batch size较大时内存消耗高
- 需要标签:相比无监督对比学习,需要标注数据
- 超参数敏感:温度参数等需要仔细调优
与其他方法的关系
vs. 交叉熵损失
- 交叉熵:关注样本-分类器匹配
- SupCon:关注样本-样本关系
- 结合使用:SupCon + CE 通常效果最好
vs. 无监督对比学习
- SimCLR/MoCo:正样本是同一图像的不同视图
- SupCon:正样本是同一类别的所有样本
- 优势:SupCon利用标签信息,正样本对更明确
vs. 三元组损失
- 三元组损失:每次只考虑一个正样本和一个负样本
- SupCon:同时考虑所有正样本和负样本
- 优势:SupCon的梯度更稳定,训练更高效
应用场景
- 图像分类:提升分类精度和鲁棒性
- 长尾学习:在类别不平衡数据上表现优异
- 少样本学习:学习到的表示泛化能力强
- 鲁棒性训练:提升模型对对抗攻击的防御能力
总结
监督对比学习通过将标签信息融入对比学习框架,成功结合了监督学习和对比学习的优势。其核心思想是:同类样本应该聚集,异类样本应该分离。通过显式优化样本间的相似性关系,SupCon学习到的表示更具判别性、鲁棒性和泛化能力。
SupCon的提出证明了对比学习不仅适用于无监督场景,在监督学习中同样有效,为后续的对比学习研究提供了重要启发。
参考文献
Khosla, P., et al. (2020). Supervised Contrastive Learning. Advances in Neural Information Processing Systems, 33. https://arxiv.org/pdf/2004.11362
Chen, T., et al. (2020). A Simple Framework for Contrastive Learning of Visual Representations. ICML 2020.
He, K., et al. (2020). Momentum Contrast for Unsupervised Visual Representation Learning. CVPR 2020.
Hadsell, R., Chopra, S., & LeCun, Y. (2006). Dimensionality reduction by learning an invariant mapping. CVPR 2006.
思考题
- 为什么监督对比学习比交叉熵损失更能提升模型的鲁棒性?
- 温度参数如何影响模型的学习?如何选择合适的?
- 在类别数量很多的情况下,SupCon损失的计算复杂度如何?如何优化?
- SupCon与交叉熵损失结合使用时,如何平衡两者的权重?
- 监督对比学习在少样本学习场景下的优势是什么?
思考题答案
1. 为什么监督对比学习比交叉熵损失更能提升模型的鲁棒性?
原因分析:
表示学习方式不同:
- 交叉熵:只关注样本与分类器权重的匹配,可能学到与分类器相关的脆弱特征
- SupCon:直接优化样本间的相似性,学习到更本质的表示
梯度特性:
- 交叉熵:梯度只来自当前样本与分类器的匹配
- SupCon:梯度来自所有同类和异类样本,信息更丰富,训练更稳定
特征空间结构:
- 交叉熵:可能形成不规则的决策边界
- SupCon:显式地拉近同类、推远异类,形成更紧凑的类内分布和更大的类间间隔
对噪声的鲁棒性:
- SupCon通过对比学习,模型学会关注样本间的相对关系而非绝对特征,对噪声更鲁棒
2. 温度参数如何影响模型的学习?如何选择合适的?
的影响:
较小(如0.05):
- 分布更尖锐,模型更关注困难样本(hard negatives)
- 学习到的表示区分性更强
- 但可能训练不稳定,容易过拟合
较大(如0.2):
- 分布更平滑,对所有样本的关注更均匀
- 训练更稳定
- 但可能学习到的表示区分性较弱
选择策略:
- 起始值:从0.07开始(论文推荐值)
- 观察训练曲线:
- 如果损失下降很快但验证集性能差 → 降低
- 如果训练不稳定或损失不下降 → 提高
- 网格搜索:在[0.05, 0.1, 0.15, 0.2]范围内搜索
- 任务相关:
- 细粒度分类(类别相似度高)→ 较小的
- 粗粒度分类(类别差异大)→ 较大的
3. 在类别数量很多的情况下,SupCon损失的计算复杂度如何?如何优化?
复杂度分析:
- 时间复杂度:,其中是batch size,是特征维度
- 空间复杂度:(相似度矩阵)
优化策略:
减小batch size:
- 使用梯度累积保持有效batch size
- 或使用负样本采样(但会损失部分性能)
混合精度训练:
- 使用FP16/BF16降低内存和计算成本
分布式训练:
- 将batch分散到多个GPU,每个GPU计算部分损失
近似方法:
- 只计算部分负样本(如hard negative mining)
- 使用memory bank存储历史特征(类似MoCo)
损失近似:
- 使用NCE(Noise Contrastive Estimation)近似
- 或使用采样方法估计分母
4. SupCon与交叉熵损失结合使用时,如何平衡两者的权重?
结合方式:
$$ \mathcal{L}_{total} = \lambda_{sup} \mathcal{L}_{sup} + \lambda_{ce} \mathcal{L}_{ce} $$
权重选择策略:
等权重:(常见起始点)
动态调整:
- 早期训练:较大,学习好的表示
- 后期训练:较大,微调分类边界
任务相关:
- 如果表示学习更重要(如few-shot)→ 增大
- 如果分类精度更重要 → 增大
实验验证:
- 在验证集上搜索:
- 通常效果较好
注意事项:
- 两个损失的尺度可能不同,需要归一化或调整权重
- 可以先用SupCon预训练,再用CE微调
5. 监督对比学习在少样本学习场景下的优势是什么?
优势分析:
更好的表示学习:
- SupCon学习到的特征更具判别性和泛化能力
- 即使样本少,也能学到类别的本质特征
类内紧凑性:
- 显式拉近同类样本,形成紧凑的类内分布
- 在少样本情况下,这有助于减少类内方差
类间分离性:
- 显式推远异类样本,增大类间间隔
- 在少样本情况下,这有助于提高分类精度
数据效率:
- 每个样本都参与多个正样本对和负样本对的学习
- 充分利用有限的标注数据
泛化能力:
- 学习到的表示对数据增强、噪声等更鲁棒
- 在测试时遇到新样本时泛化更好
实际应用:
- 在few-shot learning中,先用SupCon在base classes上预训练
- 然后在novel classes上用few-shot learning方法微调
- 通常能取得比直接使用交叉熵更好的效果
 微信
微信