
Masked Autoencoders Are Scalable Vision Learners
引言
MAE (Masked Autoencoders) 由He Kaiming团队在2021年提出,为视觉自监督学习带来了新的范式。论文标题“Masked Autoencoders Are Scalable Vision Learners”凸显了其两大特性:一是基于掩码的自重构任务;二是能在大规模数据和模型上稳定扩展。和SimCLR、MoCo等对比学习方法相比,MAE丢弃了昂贵的负样本构造环节,通过简单的遮挡-重建目标即可学习高质量的视觉特征。
在图像理解任务中,过去的自监督方法往往依赖对比学习或生成式建模。MAE将NLP中成熟的Masked Language Modeling理念迁移到视觉领域,将图片切分为patch token,然后随机遮挡大部分token,让模型仅凭剩余少量可见token推断出被遮挡的像素,从而学到上下文结构。
背景知识
自监督视觉预训练的演进
- 预文本任务 (Pretext Task):如旋转预测、拼图恢复等,但任务与下游语义差距较大。
- 对比学习时代:SimCLR、MoCo、BYOL通过实例判别与数据增强获得强特征,但需要大batch或额外队列。
- 生成式方法回潮:iGPT、VQ-VAE尝试像素重建,但计算成本高、收敛慢。
- Vision Transformer普及:ViT把图像转成patch序列,为视觉领域引入“token”概念,使得掩码预测成为可能。
MAE正是在ViT基础上发展的生成式自监督方法。
自动编码器 vs. 对比学习
| 特性 | 自动编码器 | 对比学习 |
|---|---|---|
| 目标 | 自重构输入 | 拉近正样本、推远负样本 |
| 数据增强依赖 | 低 | 高 |
| 训练稳定性 | 较稳定 | 依赖大batch/动量队列 |
| 计算需求 | 可低(MAE只编码可见token) | 往往高 |
| 表征性质 | 偏向局部+全局 | 偏向判别特征 |
MAE融合了自动编码器的补全思想与Transformer的全局建模能力。
论文核心思想
主要贡献
- 高掩码率:高达75%~90%的随机遮挡仍能有效预训练,极大降低计算量。
- 轻量解码器:编码器专注表示学习,解码器仅用于预训练阶段重建。
- 非对称架构:编码器处理少量可见token,解码器负责重建全部token,简化了训练。
- 可扩展性:在ImageNet上与有监督预训练相当甚至更优,对下游检测、分割任务具备竞争力。
整体流程
1 | 输入图像 → Patch划分 → 随机掩码 → 编码器处理可见patch → 嵌入掩码token → 轻量解码器重建像素 → 计算重建损失 |
模型架构
Patch Embedding 与 ViT兼容性
- 使用ViT相同的patchify方式:将图像划分为
16×16的patch,拼接成序列。 - 对每个patch做线性投影得到
D维token,并加上位置编码。 - 由于MAE后续要还原像素,额外保存patch形状信息用于unpatchify。
随机掩码策略
- 均匀随机:从所有patch中随机采样保留25%,掩码75%。
- 可见token排序:保留patch在顺序上也会随机打乱,增加任务难度。
- 原因:视觉信息冗余高,遮挡大部分区域仍能推断结构,训练效率也随掩码率提高而提高。
编码器(Encoder)
- 直接使用标准ViT Backbone(如ViT-B/16)。
- 输入仅限可见token,大幅减少自注意力计算量。
- 由于只处理25%的token,训练速度提高约3~4倍。
解码器(Decoder)
- 结构比编码器浅(如8层Transformer),隐藏维度更小(如512)。
- 输入由“编码器输出的可见token + 掩码token嵌入”组成。
- 仅在预训练阶段存在,下游微调时丢弃,避免增加推理成本。
重建目标
- 对所有patch输出预测像素,常用均方误差(MSE)。
- 论文采用归一化的pixel值(对每个patch做均值方差归一),提升稳定性。
- 也可以替换为DCT系数、特征空间等,扩展空间很大。
训练策略
预训练设置
| 配置 | 常用取值 |
|---|---|
| 数据集 | ImageNet-1K无标签 |
| 掩码率 | 75% |
| Patch size | 16 |
| 训练时长 | 400 epoch |
| 优化器 | AdamW (lr=1.5e-4, weight decay=0.05) |
| 学习率策略 | Cosine + warmup |
| 数据增强 | 仅RandomResizeCrop + 随机水平翻转 |
微调策略
- 使用预训练好的编码器权重初始化ViT Backbone。
- 替换为任务特定头(分类、检测、分割)。
- 学习率通常更小(如5e-4),训练epoch也减少(如100 epoch)。
- 对分类任务,还会加入Mixup、CutMix等常规增强。
Linear Probe & KNN
- 冻结编码器,仅训练线性分类头,可评估特征线性可分性。
- 5-NN评估也常用来衡量无监督表示质量。
实验结果
ImageNet分类
| 模型 | 预训练方式 | Top-1 Acc |
|---|---|---|
| ViT-B/16 (监督) | 有标签 | 81.8% |
| ViT-B/16 (MAE) | 400 epoch | 83.7% |
| ViT-L/16 (MAE) | 400 epoch | 85.9% |
MAE在有限标注下游训练(如少量epoch)同样保持优势。
下游任务
- 目标检测 (COCO):与有监督预训练持平甚至略优。
- 语义分割 (ADE20K):微调后比监督预训练高1~2 mIoU。
- 鲁棒性:对遮挡和噪声具有更强适应性。
消融实验
- 掩码率:75%最佳,过低浪费计算,过高训练不稳定。
- 解码器深度:浅层即可,过深收益有限。
- 重建目标:直接像素即可,无需复杂loss。
- 位置编码:无需额外改动,使用ViT默认编码即可。
表征分析
- MAE倾向关注全局结构,对局部纹理不过拟合。
- 可视化显示模型能推断出缺失的主体轮廓,说明捕捉到高层语义。
- 线性探针结果表明特征具备良好的线性可分性。
代码实现要点
基础组件
1 | import torch |
随机掩码函数
1 | def random_masking(x, mask_ratio=0.75): |
训练循环示例
1 | def mae_forward(model, imgs, mask_ratio=0.75): |
PyTorch Lightning/Timm 的现成实现
timm.models.mae提供官方实现,可直接加载mae_vit_base_patch16等模型。- Hugging Face Transformers也提供
Mask2Former等派生实现。
工程实践建议
- Mixed Precision:配合高掩码率,训练非常高效。
- 数据增强:预训练阶段增强较轻,避免破坏像素重建难度;微调阶段再加重。
- 学习率调试:预训练用较大学习率,微调用较小的学习率。
- 梯度累计:若显存受限,可结合梯度累计保持批量大小。
与其他方法的比较
| 模型 | 训练范式 | 计算需求 | 表征特点 |
|---|---|---|---|
| MAE | 掩码重建 | 低 (编码少量token) | 全局语义强 |
| BEiT | Token重建 | 中 (需tokenizer) | 依赖dVAE词表 |
| SimMIM | 像素重建 | 中等 | 无解码器分离 |
| MaskFeat | HOG特征重建 | 中 | 更注重低级特征 |
MAE以简单高效著称,成为后续大量工作(如MaskFeat、iBOT)的基础。
优缺点总结
优点
- 训练高效:编码器只处理可见token,显著降低计算。
- 鲁棒性强:对遮挡与噪声有更好表现。
- 迁移能力好:分类、检测、分割任务均有优势。
- 实现简单:无须复杂的数据增强或对比对。
缺点
- 重建目标限制:重建像素可能关注低级细节,对高层语义关注不足。
- 遮挡策略固定:随机掩码未利用场景先验,对结构化遮挡可能欠佳。
- 不适合生成:目标是补全而非生成高质量图像。
- 超参数敏感:掩码率、解码器宽度等需要调优。
相关与后续工作
- MAE v2:引入多尺度特征、更强的数据增强。
- SimMIM / MaskFeat:探索不同重建目标(直接像素、HOG等)。
- MaskCLIP:结合跨模态信息,用文本引导掩码学习。
- Masked Siamese Networks:将掩码与对比学习结合。
- VideoMAE:扩展到视频,随机掩码时空patch。
总结
MAE通过高掩码率的自重构任务,在不依赖负样本对的情况下实现了高质量的视觉自监督学习。其关键在于:
- 非对称架构:编码器轻量输入,解码器仅用于训练。
- 高掩码率:降低计算同时保持学习难度。
- 贴近NLP的设计:借鉴MLM理念,实现跨模态迁移。
MAE证明了生成式自监督在视觉任务中的可行性,为后续的Mask-based预训练方法奠定了基础。
参考文献
- He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2021). Masked autoencoders are scalable vision learners. arXiv:2111.06377.
- Dosovitskiy, A., et al. (2020). An image is worth 16x16 words: Transformers for image recognition at scale.
- Bao, H., Dong, L., & Wei, F. (2021). BEiT: BERT Pre-Training of Image Transformers.
- Xie, Z., et al. (2022). SimMIM: A Simple Framework for Masked Image Modeling.
思考题
- 为什么MAE可以使用75%的高掩码率?是否存在场景需要降低掩码率?
- 解码器仅用于预训练阶段,是否意味着我们可以用更复杂的解码器来提升效果?
- MAE的像素重建目标会不会让模型学到过多低级特征?如果是,该如何改进?
- 与对比学习相比,MAE缺少显式的判别约束,如何弥补这一点?
- 如果要把MAE扩展到视频或多模态任务,需要额外注意哪些设计?
思考题答案
1. 为什么MAE可以使用75%的高掩码率?是否需要调整?
- 图像存在大量冗余,局部区域通常可由上下文推断。
- Transformer具备全局建模能力,即便仅看到25%的patch也能捕捉结构。
- 高掩码率减少计算成本;在纹理细节极其丰富的任务(如医学影像)可以适当调低(如50%)以保证信息量。
2. 解码器能否更复杂?
- 理论上可以,但实验表明解码器过深收益有限,且增加训练成本。
- 解码器主要提供学习信号,过强的解码器会掩盖编码器能力。
- 若要改进,不如让解码器重建更高层次表征(如语义分割mask)。
3. 像素重建是否导致偏向低级细节?
- 像素Loss会促使模型拟合纹理,但高掩码率迫使模型理解结构。
- 可通过重建特征空间(如DINO特征)、频域信息或多任务损失提升语义理解。
4. 如何引入判别约束?
- 在MAE基础上叠加对比学习头(如MAE+MoCo)。
- 结合监督信号(半监督设置)或知识蒸馏。
- 在线性探针阶段引入额外的判别任务。
5. 拓展到视频或多模态的注意点
- 视频:需要处理时序维度,可随机掩码时空patch,并采用时序位置编码。
- 多模态(图文):需联合掩码不同模态,并设计跨模态对齐目标,如重建文本描述。
- 计算资源:视频/多模态数据更大,掩码率、模型尺寸需兼顾效率。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 WPIRONMAN!
 微信
微信
相关推荐
2025-11-09
BERT详解 - 双向编码器表示模型精读
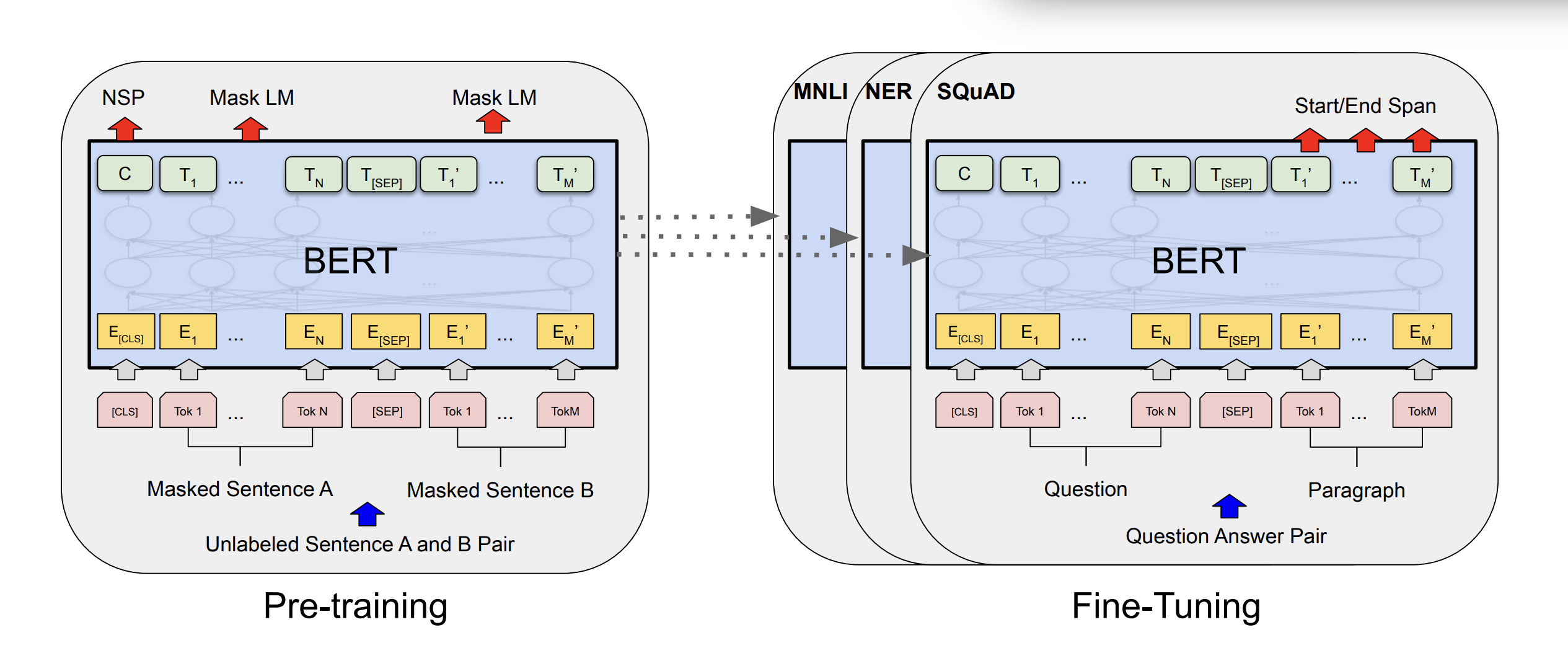
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 引言 BERT (Bidirectional Encoder Representations from Transformers) 是Google在2018年提出的革命性自然语言处理模型,它通过在无标注文本上进行预训练,学习深层的双向语言表示,在下游任务上取得了突破性的成果。 BERT的核心创新在于双向上下文编码,与之前的ELMo(浅层双向)和GPT(单向)不同,BERT使用Transformer编码器同时利用上下文信息,彻底改变了NLP领域的预训练范式。 背景知识 预训练语言模型的发展 在BERT之前,主流的预训练方法存在以下局限性: 单向语言模型(如GPT):只能从左到右或从右到左进行编码,无法同时利用双向上下文 浅层双向模型(如ELMo):虽然考虑了双向信息,但只是简单拼接左右向表示,而非深度双向,网络架构比较老,使用的RNN 为什么需要双向编码? 语言的理解往往需要同时考虑前后文信息。例如: “银行”...
2025-04-18
CSRMS
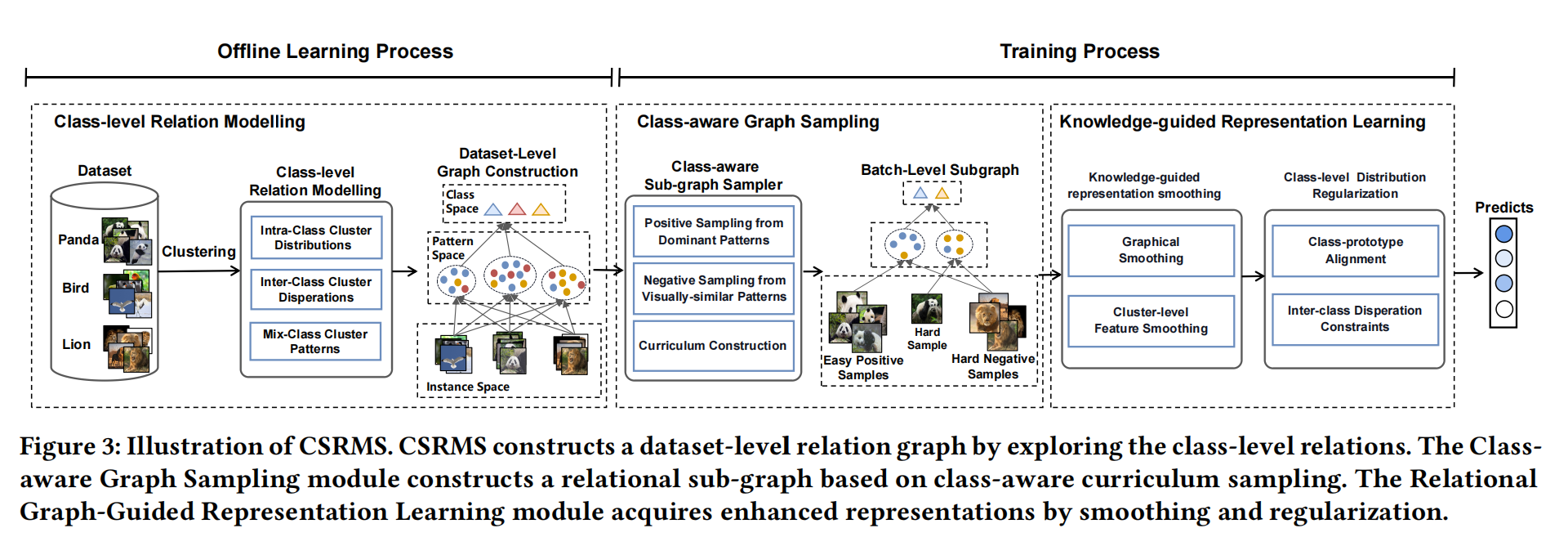
CSRMS 用于视觉表征学习的类级结构化关系建模与平滑 (MM2023) 论文地址:https://ercdm.sdu.edu.cn/__local/7/AC/70/7E4948C4761839F62E3958CE772_043AE854_2B459A.pdf 代码地址:https://github.com/czt117/CSRMS 个人理解这个像是一个知识总结的过程。首先通过特征提取获得特征图,这个过程可以类比我从书本上学习知识的过程,提取出有用的知识,然后通过聚类算法对特征图进行分簇,就相当于把学到的知识进行总结的过程,但是总会有一些比较相近的知识容易被搞混,这个就是类间相似性和类内多样性,再着重对这一块进行处理,使得对知识的掌握更加透彻。 名词解释: 课程构建(Curriculum...

2025-11-09
Mamba详解 - 选择性状态空间模型精读
Mamba: Linear-Time Sequence Modeling with Selective SSMs 论文地址:https://arxiv.org/pdf/2312.00752 代码地址:https://github.com/state-spaces/mamba 引言 Mamba 是一种基于状态空间模型(State Space Model, SSM)的高效序列建模框架,旨在在保持强表达能力的同时,将计算与内存复杂度降至与序列长度线性相关。与Transformer的二次复杂度相比,Mamba在超长序列、低时延和内存受限场景中具有显著优势。 Mamba的核心在于“选择性扫描(Selective Scan)”与“输入依赖的状态转移”,通过对经典S4(Structured State Space Sequence Model)的工程化与理论改进,实现端到端可训练、GPU友好、且具有SOTA性能的线性时间序列模型。 背景知识:状态空间模型(SSM)与S4 连续与离散SSM 连续时间SSM: $$ \dot x(t) = A x(t) + B u(t), \quad y(t)...

2025-09-10
MambaOut
MambaOut MambaOut: Do We Really Need Mamba for Vision? (CVPR...
2025-04-27
MoE
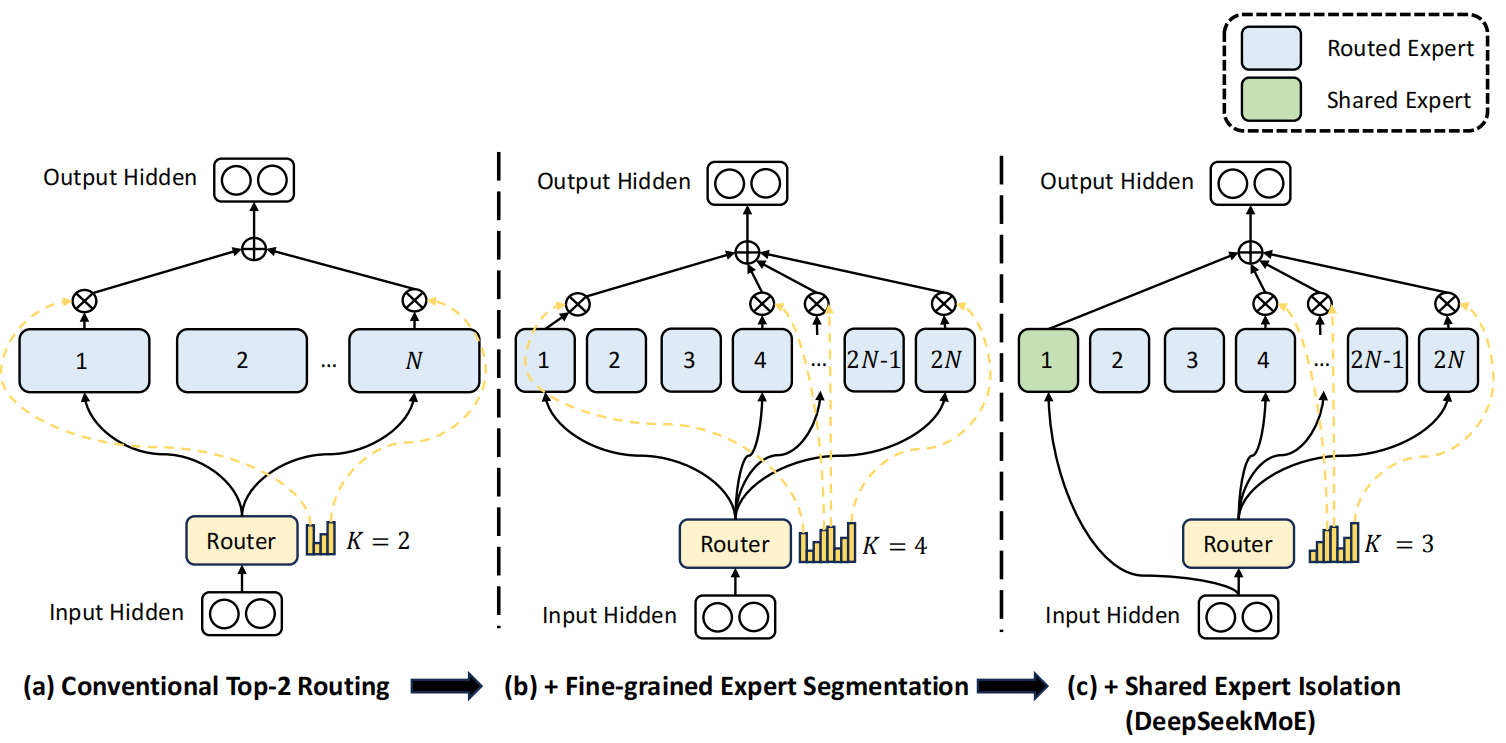
Mixtures of Experts 《Adaptive Mixture of Local Experts》 论文链接:https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf 1991年,由 Hinton和 Jordan提出,这是最早的MoE架构。 核心思想:通过多个独立专家网络处理输入数据不同子集,并由门控网络动态选择专家。每个专家接受相同的输入数据,但通过门控网络的动态分配,专家会专注于处理输入空间的特定区域。 基础架构 如图,一个由专家网络和门控网络组成的系统。每个专家是一个前馈网络,所有专家接收相同的输入,并具有相同数量的输出。门控网络也是一个前馈网络,通常接收与专家网络相同的输入。它的输出是归一化的 $ p_j = \exp(r_j) / \sum_i \exp(r_i) $,其中 $ r_j $是门控网络输出单元 $j$ 接收的总加权输入。选择器(selector)类似于一个多输入单输出的随机开关;开关选择来自专家 $ j $ 的输出的概率为 $p_j$...
2025-04-24
MoCo
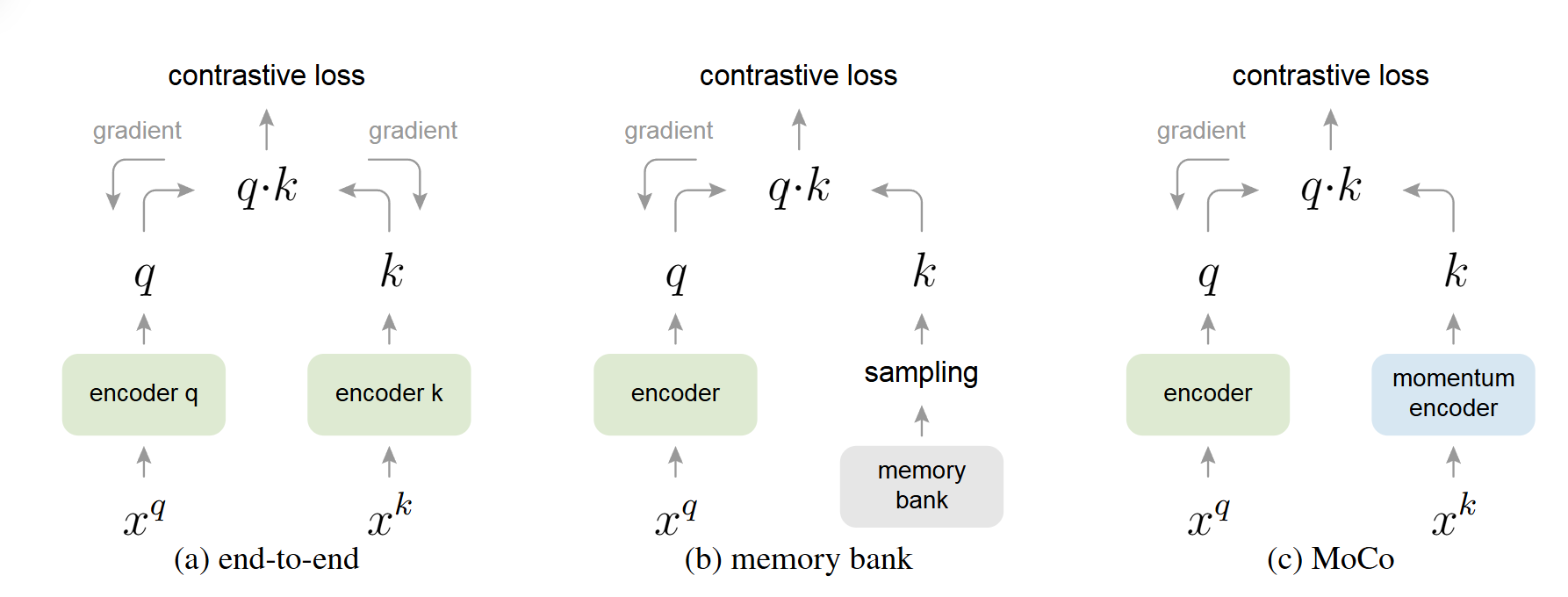
MoCo Momentum Contrast for Unsupervised Visual Representation Learning (cvpr2020) 论文地址:https://arxiv.org/pdf/1911.05722 代码地址:https://github.com/facebookresearch/moco 概述 MoCo 将对比学习看作是一个字典查找任务 :一个编码后的查询(query)应该与其匹配的键(正样本)相似,而与其他所有的键(负样本)不相似 。 对比学习的核心思想是训练一个编码器,使其能够区分相似(正样本)和不相似(负样本)的样本 。 传统方法 VS MoCo 端到端(End-to-end)方法(SimCLR,Inva Spread):将当前 mini-batch 内的样本作为字典 。这种方法的优点是字典中的键编码是一致的(由同一个编码器生成),但缺点是字典的大小受限于 mini-batch 的大小,而 mini-batch 大小又受限于 GPU 内存 。过大的 mini-batch 也会带来优化难题 。 Memory Bank...
评论