
在深度学习中,损失函数 (Loss Function) 是连接模型预测与真实标签的桥梁,它定义了模型的优化目标。选择合适的损失函数往往能起到事半功倍的效果。本文将对深度学习中常见的损失函数进行梳理,从基础的回归/分类到进阶的难例挖掘和度量学习。
1. 回归任务 (Regression)
回归任务的目标是预测连续值。
1.1 MSE (L2 Loss)
均方误差 (Mean Squared Error):
$$ L = (y - \hat{y})^2 $$
- 特点:收敛快,但对异常值 (Outliers) 非常敏感(因为误差被平方放大了)。
1.2 MAE (L1 Loss)
平均绝对误差 (Mean Absolute Error):
$$ L = |y - \hat{y}| $$
- 特点:对异常值鲁棒,但在 0 点处不可导,梯度恒定可能导致收敛困难。
1.3 Smooth L1 Loss
结合了 L1 和 L2 的优点:
- 在误差较小时($|x| < 1$)使用 L2(平滑,可导)。
- 在误差较大时($|x| \ge 1$)使用 L1(梯度恒定,防止梯度爆炸)。
- 应用:Faster R-CNN 的边界框回归。
2. 分类任务 (Classification)
2.1 Cross Entropy (CE)
交叉熵损失是分类任务的标准配置:
$$ CE = - \sum y \log(p) $$
- 本质:衡量两个概率分布的距离(KL 散度)。
- 局限:对噪声标签敏感,且容易导致模型过度自信 (Over-confidence)。
2.2 Label Smoothing
为了解决 CE 的过度自信,Label Smoothing 将 One-hot 标签软化:
$$ y_{new} = (1 - \epsilon) y + \epsilon / K $$
- 作用:防止模型在训练集上过拟合,提升泛化能力。
3. 进阶:解决不平衡与难例
当数据存在严重的类别不平衡或大量简单负样本时,标准 CE 往往失效。
3.1 Focal Loss
最初用于目标检测 (RetinaNet),旨在解决 One-stage 检测器中极端的正负样本失衡。
- 公式:$FL(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t)$
- 核心机制:
- $\gamma$ (Focusing Parameter):降低易分样本($p_t \approx 1$)的权重,迫使模型关注难分样本。
- $\alpha$ (Balancing Parameter):平衡正负样本比例。
- 价值:不仅用于检测,在长尾分类任务中也非常有效。
1 | # Focal Loss PyTorch 实现 |
4. 进阶:度量学习 (Metric Learning)
目标是学习一个特征空间,使得同类样本距离近,异类样本距离远。
4.1 Triplet Loss
$$ L = \max(d(a, p) - d(a, n) + margin, 0) $$
- 输入:三元组 (Anchor, Positive, Negative)。
- 难点:需要复杂的三元组挖掘 (Triplet Mining) 策略,否则训练效率极低。
4.2 InfoNCE (Contrastive Loss)
自监督学习(如 SimCLR, MoCo)的核心。
- 思想:将 Triplet 扩展到 N 个负样本,转化为一个 N+1 类的分类问题。
- 优势:利用大量负样本,学习到的特征更具判别性。
总结
- 回归:首选 Smooth L1 或 MSE。
- 分类:首选 Cross Entropy,配合 Label Smoothing。
- 不平衡/难例:必选 Focal Loss。
- 特征学习:尝试 InfoNCE 或 Triplet Loss。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 WPIRONMAN!
 微信
微信
相关推荐

2025-04-15
基于深度学习的图像分类
使用ResNet18预训练模型 由于笔记本性能太差,所以在服务器上运行的,显卡配置为4090。经大量实验判断,初始学习率为0.01最后效果较差,所以初始学习率应设为0.001。全部代码代码已上传到:https://github.com/wp-a/-CIFAR10-.git 库函数导入 123456789import matplotlib.pyplot as pltimport torchimport torch.nn as nnimport torchvisionimport torchvision.transforms as transformsfrom sklearn.metrics import confusion_matrix, classification_reportfrom itertools import chainimport multiprocessingdevice = torch.device("cuda:0" if torch.cuda.is_available() else...

2025-11-13
对比学习综述
对比学习综述:从理论到实践全面解析 引言 对比学习(Contrastive Learning) 是近年来自监督学习领域最重要的突破之一,它通过"拉近正样本、推远负样本"的简单思想,在无需大量标注数据的情况下学习到强大的视觉表示。从2020年的SimCLR、MoCo开始,对比学习在ImageNet等基准上取得了与监督学习相当甚至更好的性能,彻底改变了我们对无监督表示学习的认知。 对比学习的核心优势在于: 无需标注数据:可以在海量无标注图像上预训练 学习鲁棒表示:对数据增强、噪声等具有强鲁棒性 迁移能力强:预训练的特征在下游任务上表现优异 可扩展性好:可以轻松扩展到大规模数据和模型 什么是对比学习? 核心思想 对比学习的核心思想可以用一句话概括:通过对比正样本对和负样本对,学习到区分性的表示。 正样本对(Positive Pairs):应该相似的样本对 无监督:同一图像的不同增强视图 有监督:同一类别的不同样本 负样本对(Negative...

2025-12-03
深度学习优化器全家桶:从 SGD 到 AdamW 及未来
在深度学习的训练过程中,优化器 (Optimizer) 扮演着至关重要的角色。它决定了网络参数更新的方式,直接影响模型的收敛速度和最终性能。本文将深入剖析深度学习中常见的优化器,从最基础的 SGD 到目前最流行的 AdamW,以及一些前沿的变体。 1. 梯度下降家族 (Gradient Descent Variants) 1.1 BGD, SGD 与 Mini-batch SGD BGD (Batch Gradient Descent):每次迭代使用全部样本计算梯度。 优点:梯度准确,收敛稳定。 缺点:计算量大,内存无法承受,无法在线更新。 SGD (Stochastic Gradient Descent):每次迭代使用一个样本。 优点:计算快,引入噪声有助于跳出局部最优。 缺点:震荡剧烈,收敛慢,无法利用向量化加速。 Mini-batch SGD:折中方案,每次使用一批样本(如 32, 64)。这是实际中最常用的形式。 $$ w_{t+1} = w_t - \eta \cdot \nabla L(w_t) $$ 1.2 Momentum (动量法) 为了抑制...

2025-11-27
深度学习杂谈:残差、MAE与特征维度的本质思考
最近有一些问题,正好记录下来了一些,用AI探讨了一下这些问题。 1. 残差 (Residual) 的本质:仅仅是保留原始信息吗? 问题: 残差的本质是什么?为什么有用?是因为保留了之前的原始信息的特征吗?那么添加动量 (Momentum) 也是保留之前的原始信息,和残差的本质有什么区别吗? 残差连接 (Skip Connection) 残差网络 (ResNet) 的核心公式是 $y = F(x) + x$。 确实,从直观上看,$+x$ 这一项直接将上一层的原始信息“保留”并传递到了下一层。这使得网络在初始化阶段即使 $F(x)$ 接近于 0,整个网络也近似于一个恒等映射 (Identity Mapping),梯度可以无损地反向传播。 本质区别: 残差 (ResNet) 解决的是 模型结构 (Model Architecture) 和 梯度流 (Gradient Flow) 的问题。它是在空间/层级维度上,让深层网络更容易训练,避免梯度消失。它让网络“有机会”去学习恒等映射,如果某一层是多余的,网络可以将 $F(x)$ 权重置为 0,自动“跳过”这一层。 动量...
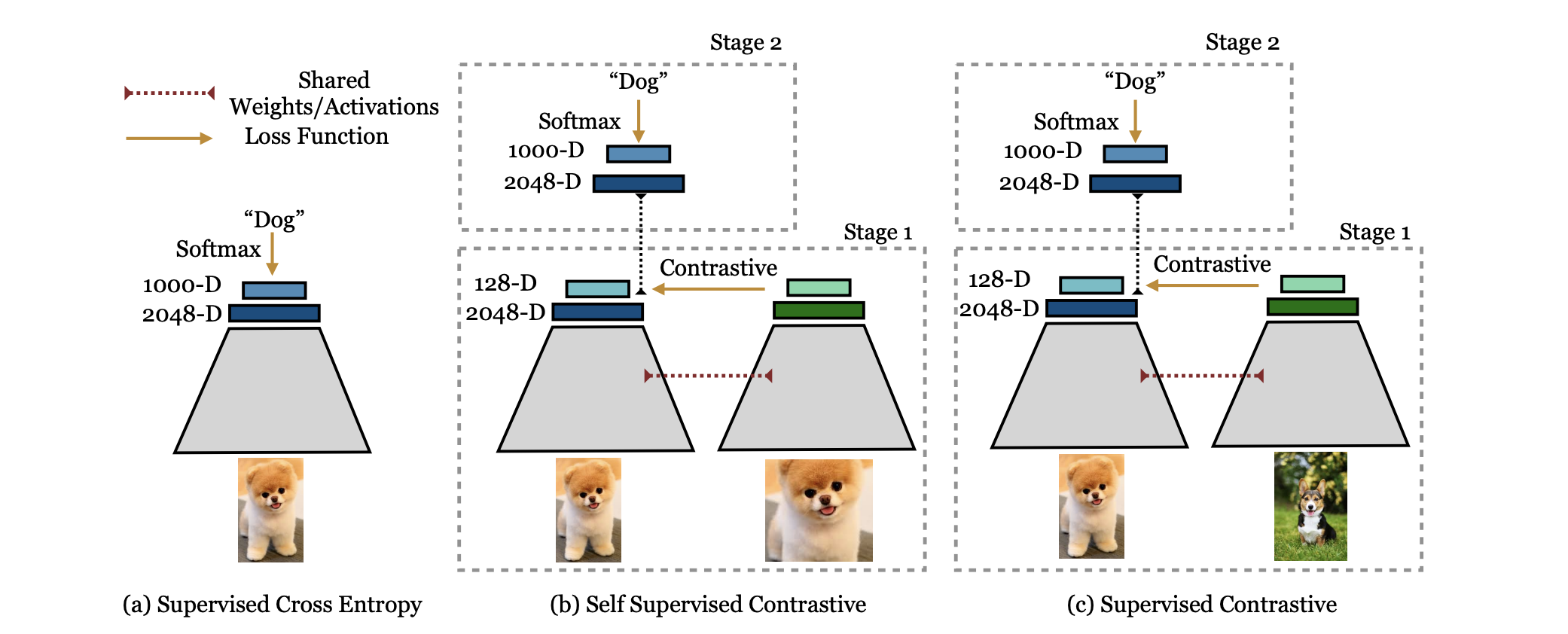
2025-11-16
监督对比学习
Supervised Contrastive Learning 论文地址:https://arxiv.org/pdf/2004.11362 代码地址:https://github.com/HobbitLong/SupContrast 引言 监督对比学习(Supervised Contrastive Learning, SupCon)...
评论