WPIRONMAN
搜索
首页
分类
项目
项目主页
学术助手
智会助手
Codex Remote PWA
技能集
AI知识星系
工地检测
AI中转控制台
WPIRONMAN Chat
友链
本站友链
随机开往
异次元之旅
学术主页
关于
归档
全部文章 - 82
2026
2026-02-09
Agentic RL:veRL(verl)训练参数理解(PPO & GRPO、Batch Size、KL & Entropy)
2026-02-09
Agentic RL:RLVR 的边界(Base vs RL、pass@k、PPL 与 vLLM 评测细节)
2026-02-09
Agentic RL:DeepSeekMath-v2 自我验证(Verifier & Meta-Verifier)
2026-02-09
Agentic RL:vLLM 参数配置、显存分析与性能调优(max_num_batched_tokens)
2026-02-09
Agentic RL:REINFORCE 4 LLM(Reward 设计与 PG+KL Loss 细节)
2026-02-09
Agentic RL:系列导航(PG Loss、TRPO、PPO-Clip)
2026-02-09
Agentic RL:从 PG 到 TRPO 到 PPO-Clip(推导与代码对齐)
2026-02-09
Agentic RL:PG Loss 组件详解(PPO-clip / Dual-Clip / Entropy / KL / 聚合)
2026-02-09
强化学习数学原理 - 第10章:Actor-Critic 方法 (Actor-Critic Methods)
2026-02-09
强化学习数学原理 - 第9章:策略梯度方法 (Policy Gradient Methods)
2026-02-09
强化学习数学原理 - 第8章:值函数近似 (Value Function Approximation)
2026-02-09
强化学习数学原理 - 第7章:时序差分方法 (Temporal-Difference Methods)
2026-02-09
强化学习数学原理 - 第6章:随机近似 (Stochastic Approximation)
2026-02-09
强化学习数学原理 - 第5章:蒙特卡洛方法 (Monte Carlo Methods)
2026-02-09
强化学习数学原理 - 第4章:值迭代与策略迭代 (Value & Policy Iteration)
2026-02-09
强化学习数学原理 - 第3章:最优状态值与贝尔曼最优方程 (Bellman Optimality)
2026-02-09
强化学习数学原理 - 第2章:贝尔曼方程 (Bellman Equation)
2026-02-09
强化学习数学原理 - 第1章:基本概念 (Basic Concepts)
2026-02-09
强化学习数学原理 - 必备数学基础 (Mathematical Preliminaries)
2026-02-09
强化学习数学原理 - 序章:一张图看懂强化学习 (Course Introduction)
上一篇
1
2
3
…
5
下一篇
WP
无业游民
文章
82
标签
192
分类
22
Follow Me
公告
学术助手已上线
期刊会议检索、前沿论文浏览和 AI 预审入口已经接进博客。
立即进入
最新文章
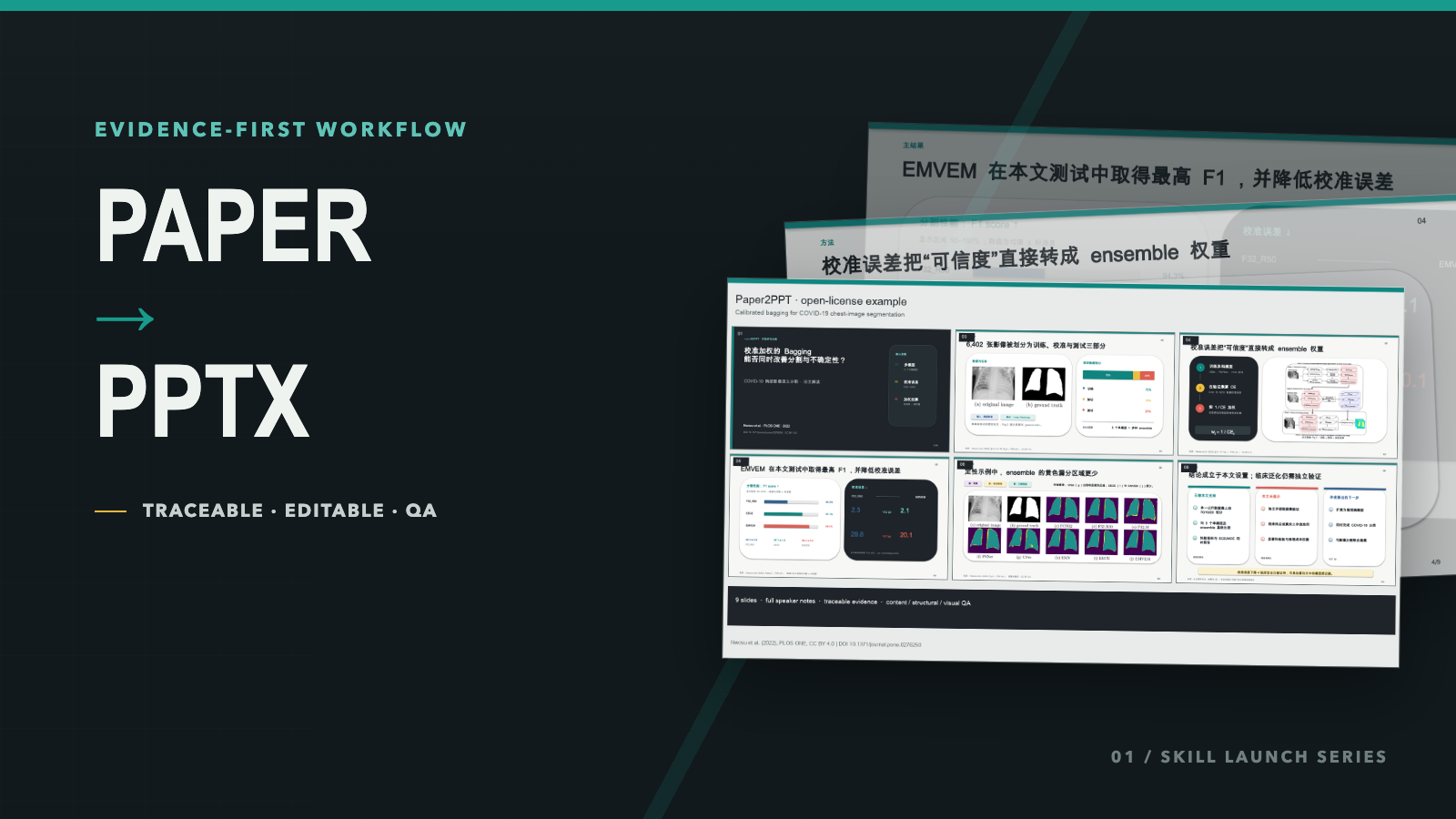
Paper2PPT:从一篇论文到可编辑、可追溯 PPTX 的证据优先工作流
2026-07-18
Academic Paper Search:可复现的多源文献检索工作流
2026-07-18
PaperRefine:论文润色不只是换同义词,而是让主张回到证据边界
2026-07-18
SOL ENGINE:把 GPT-5.6 提示词优化变成可审计、可回归的工程流程
2026-07-18
分类
学术思考
2
工程实践
12
强化学习
5
科研方法
1
强化学习数学原理
12
手撕代码
2
图像分类
2
数据结构与算法
7
标签
CleanRL
损失函数
transformer
视觉表征
Bellman Optimality
对比学习
Policy Gradient
研究生生活
algorithm
Claude Code
RLVR
SGLang
Introduction
Function Approximation
Ray
Evaluation
Batch Size
选择排序
Academic Paper Search
GRPO
Transformer
Reinforcement Learning
Lenet
SSM
字符串
Agent Loop
DPO
论文精读
堆
PyTorch
queue
deque
Verifier
vLLM
产品思考
Entropy
RLOO
Resnet
Sarsa
Self-Verification
归档
七月 2026
5
四月 2026
3
二月 2026
32
十二月 2025
5
十一月 2025
8
九月 2025
2
六月 2025
1
四月 2025
5
网站信息
文章数目 :
82
运行时间 :
本站总字数 :
186k
最后更新时间 :
总访问量:
加载中...
搜索
数据加载中
从关键词开始检索文章
适合查找算法笔记、强化学习推导、科研工作流和项目入口。
Agentic RL
Deep Research
Codex
强化学习