
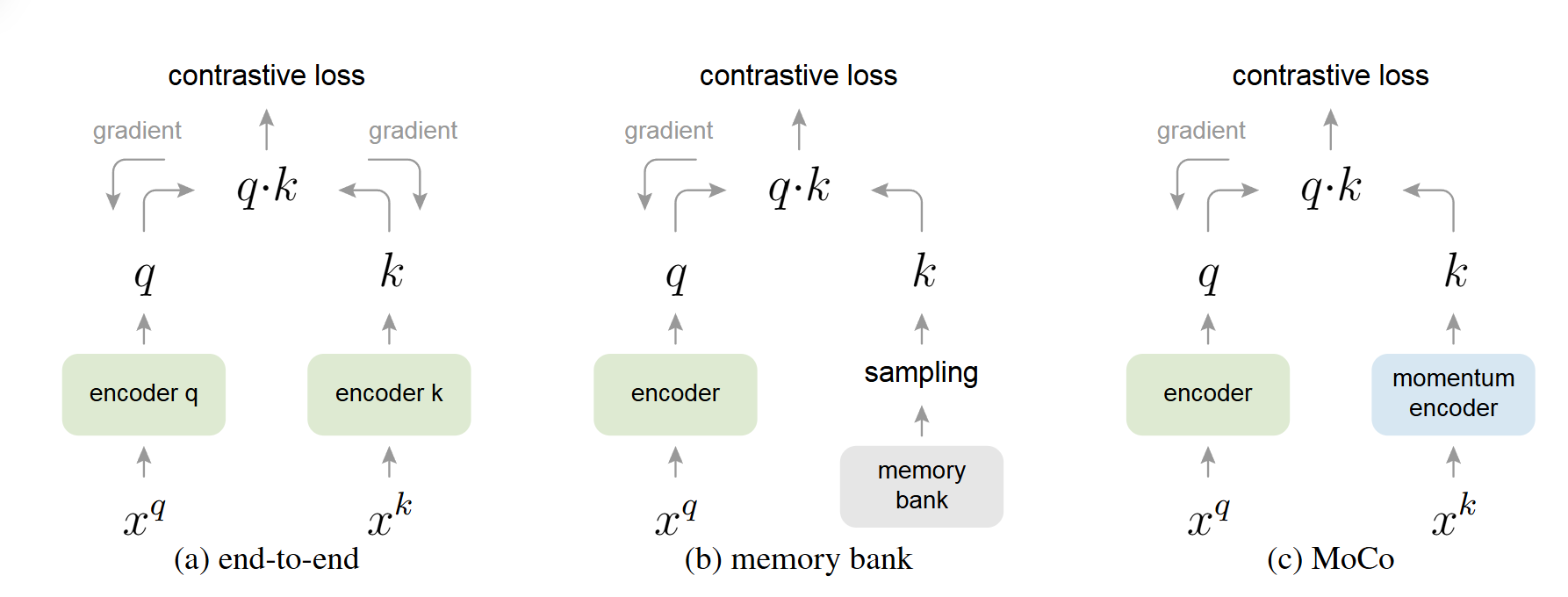
MoCo
MoCo Momentum Contrast for Unsupervised Visual Representation Learning (cvpr2020) 论文地址:https://arxiv.org/pdf/1911.05722 代码地址:https://github.com/facebookresearch/moco 概述 MoCo 将对比学习看作是一个字典查找任务 :一个编码后的查询(query)应该与其匹配的键(正样本)相似,而与其他所有的键(负样本)不相似 。 对比学习的核心思想是训练一个编码器,使其能够区分相似(正样本)和不相似(负样本)的样本 。 传统方法 VS MoCo 端到端(End-to-end)方法(SimCLR,Inva Spread):将当前 mini-batch 内的样本作为字典 。这种方法的优点是字典中的键编码是一致的(由同一个编码器生成),但缺点是字典的大小受限于 mini-batch 的大小,而 mini-batch 大小又受限于 GPU 内存 。过大的 mini-batch 也会带来优化难题 。 Memory Bank...
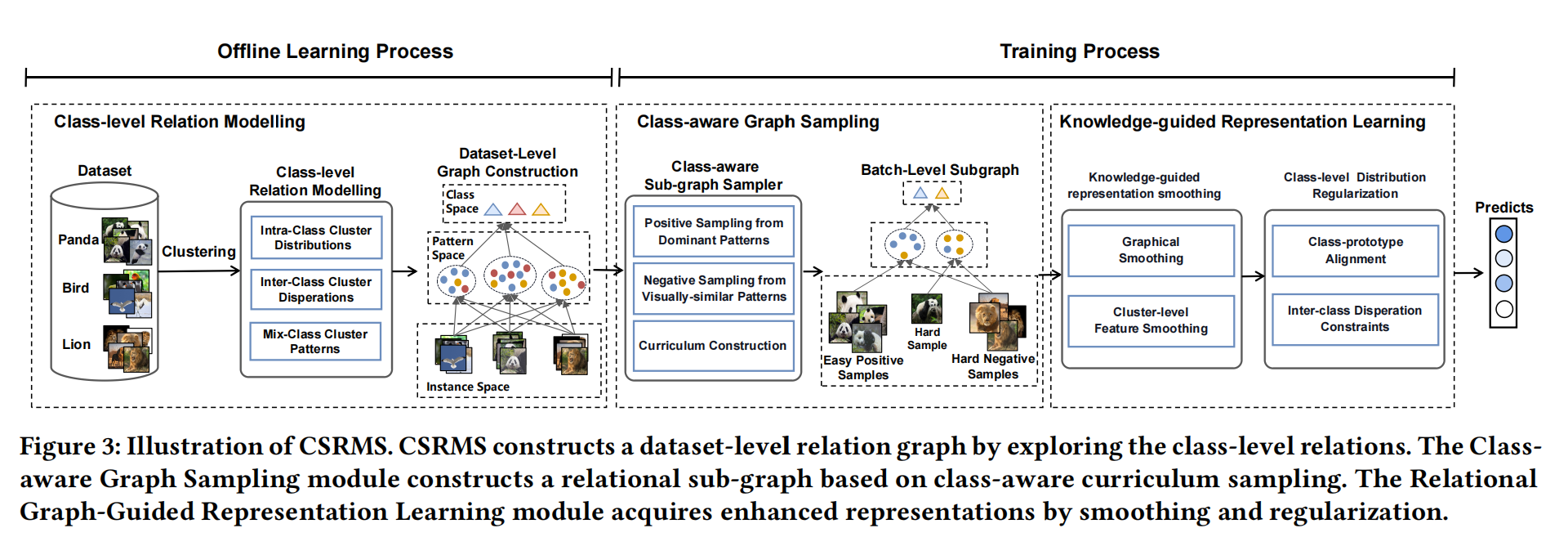
CSRMS
CSRMS 用于视觉表征学习的类级结构化关系建模与平滑 (MM2023) 论文地址:https://ercdm.sdu.edu.cn/__local/7/AC/70/7E4948C4761839F62E3958CE772_043AE854_2B459A.pdf 代码地址:https://github.com/czt117/CSRMS 个人理解这个像是一个知识总结的过程。首先通过特征提取获得特征图,这个过程可以类比我从书本上学习知识的过程,提取出有用的知识,然后通过聚类算法对特征图进行分簇,就相当于把学到的知识进行总结的过程,但是总会有一些比较相近的知识容易被搞混,这个就是类间相似性和类内多样性,再着重对这一块进行处理,使得对知识的掌握更加透彻。 名词解释: 课程构建(Curriculum...
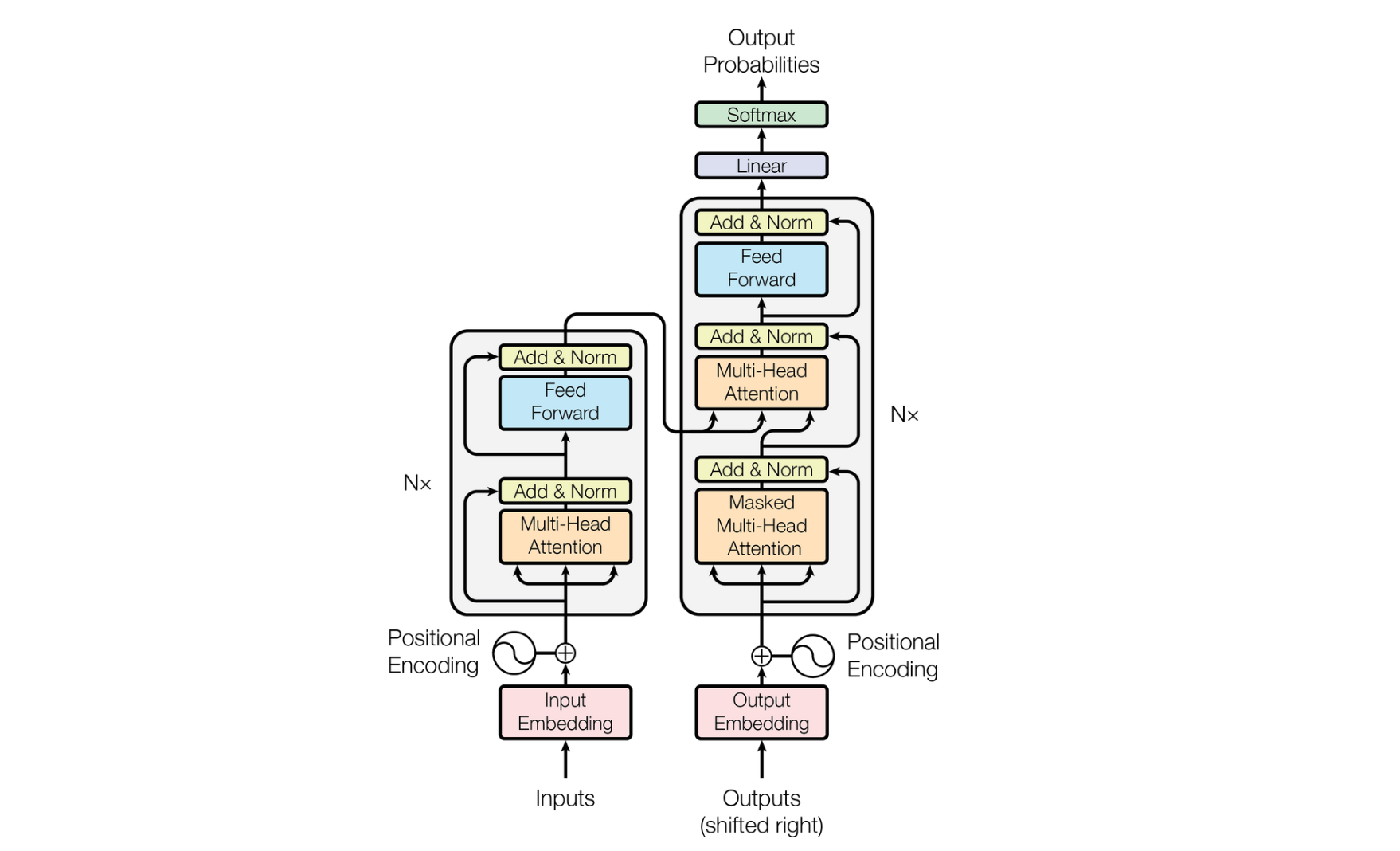
Transformer
Attention Is All You Need 个人理解 transformer 编码器是把人能理解的东西转化成计算机能理解的东西。对比与论文写作的这个过程来说,位置编码就是作者写这篇论文的顺序,反复打磨论文这个过程就对应着这个n个编码器,第一遍的初稿相当于第一个编码器,可能效果不尽人意。把人能理解的东西编码成论文。到读者来说就是解码的过程,每一次读论文就是一次解码的过程,你必须多次解码才能对这个论文理解的更加透彻,还要时刻注意mask操作,写作时要时刻注意读者理解到什么地步,读者的阅读是按顺序进行的。q就是你感兴趣的地方,k就是论文中的关键点。 Transformer 是一种基于注意力机制(Attention...

基于深度学习的图像分类
使用ResNet18预训练模型 由于笔记本性能太差,所以在服务器上运行的,显卡配置为4090。经大量实验判断,初始学习率为0.01最后效果较差,所以初始学习率应设为0.001。全部代码代码已上传到:https://github.com/wp-a/-CIFAR10-.git 库函数导入 123456789import matplotlib.pyplot as pltimport torchimport torch.nn as nnimport torchvisionimport torchvision.transforms as transformsfrom sklearn.metrics import confusion_matrix, classification_reportfrom itertools import chainimport multiprocessingdevice = torch.device("cuda:0" if torch.cuda.is_available() else...

代码随想录--动态规划
代码随想录--动态规划

基础知识--排序算法
排序算法详解 排序算法是计算机科学中最基础也是最重要的算法之一。本文将详细介绍几种常见的排序算法,包括它们的实现原理、时间复杂度和适用场景。本文所有代码示例使用 C++ 实现,需要包含以下头文件: 123#include <vector>#include <algorithm>using namespace std; 1. 冒泡排序 (Bubble Sort) 冒泡排序是最简单的排序算法之一,它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。 实现原理 时间复杂度:O(n²) 空间复杂度:O(1) 稳定性:稳定 实现代码 1234567891011121314151617void bubbleSort(vector<int>& arr) { int n = arr.size(); bool swapped; for(int i = 0; i < n-1; i++) { swapped = false; // 每一轮比较 ...
代码随想录--图论
代码随想录--图论
基础知识--图论
基础知识--图论
代码随想录--回溯算法
代码随想录--回溯算法
基础知识--回溯算法
回溯算法 回溯算法 是一种通过试错的方式寻找问题解的算法。它尝试逐步构建解决方案,如果在构建过程中的某一步发现当前的构建方案不可行,它会回溯(即取消最近一步的选择),然后尝试其他的可能性。这个过程就像是在迷宫中探索路径,当遇到死路时就退回上一个岔路口,选择另一条路继续前进。 核心思想 试探性选择: 在每一步,都面临多个选择,回溯算法会先选择其中一个进行尝试。 逐步构建: 它一步一步地构建可能的解。 可行性判断 (约束条件): 在每一步构建后,都会检查当前的部分解是否满足问题的约束条件。 回溯 (撤销选择): 如果发现当前部分解不可行,则撤销上一步的选择,回到之前的状态,并尝试其他的选择。 终止条件: 当找到一个完整的可行解,或者当所有可能的选择都尝试完毕且没有找到解时,算法终止。 基本步骤 定义问题的解空间: 确定问题的解可能存在的所有可能组合。例如,对于一个排列问题,解空间就是所有可能的排列。 确定约束条件: 定义问题解必须满足的条件。这些条件用于判断当前构建的部分解是否有效。 选择搜索策略 (通常是深度优先搜索 DFS): ...